Automate your Cover Letter with Python and mailmerge
The skills the author demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
When you look for a new position, attaching a Cover Letter to your application is very important: you want to stand out and showcase your personality and enthusiasm about the role and the company you’re applying to.
However, having to apply for dozens of positions every day turns writing cover letters a very time-consuming exercise, especially if you need all that valuable time to prepare for the actual interviews.
The best solution is to automate the routine of replacing text in the letter template while keeping the personalization.
I used this tutorial as a start and created a workflow that collects all varied text from a csv table and creates personalized ready-to-go cover letters in seconds.
And here’s how you can do that too:
Creating a docx Template for Cover Letter Template
So, first step you need to create a cover letter template and replace all “moving parts” with Merge Fields.
You can use an existing cover letter and just replace the varied text with the fields.
To do so, select the text and go to the Insert tab, click Quick Parts button and select Field…
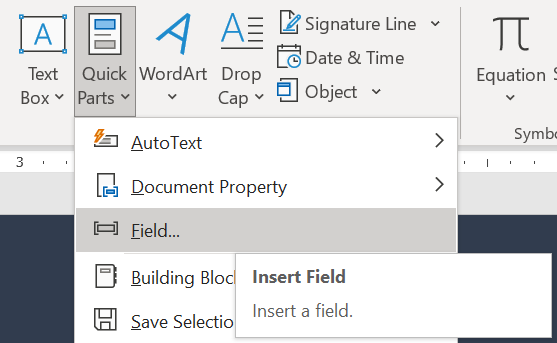
Then in the menu select MergeField and fill in the Field name and click OK:
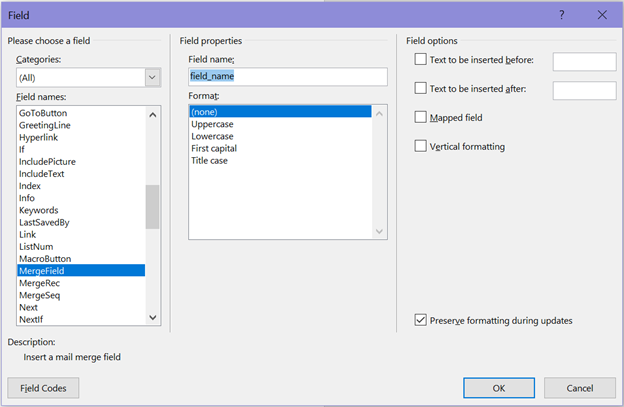
After that, the text you selected should be replaced with <<field_name>>.
Each of the fields you create in the document will be a variable name that you’ll need to reference later in the code, so be mindful of these variable names.
It is also useful to create a date using Time field in the same menu, this way the date of the cover letter will always be actual.
When you’re done, save your docx document and go to the next step.
Creating a csv table for Cover Letter Template
Then we’ll create a table in which you will fill in all varied text: company name, position name, personalized details etc.
It’s better to use the first line for variable names and make them the same as the field names you created in the docx template to avoid confusion.

Creating a Script for Template
Note: the indentations in the code blocks can be off, I haven’t found how to deal with that yet. Please refer to the code on my GitHub.
First off, you need to install a few things:
# for populating the docx template
conda install lxml
pip install docx-mailmerge
# for converting created docx files to PDF
pip install docx2pdfAnd load necessary libraries:
from __future__ import print_function
from mailmerge import MailMerge
from datetime import date
import pandas as pd
from docx2pdf import convertCreate path for your docx template and load your csv:
template = "Cover_letter_template.docx"
cl_text = pd.read_csv("cover_letter_text.csv")This chunk of code creates a list of dictionaries each of which collects all text for one cover letter:
job_lst = []
for line_num in range(cl_text.shape[0]):
job_dict = {}
for col in cl_text.columns:
job_dict[col] = cl_text.loc[line_num, col]
job_lst.append(job_dict)This chunk:
for job in job_lst:
document = MailMerge(template)
document.merge(
company_name=job['company_name'],
position_name=job['position_name'],
job_posting_source=job['job_posting_source'],
introduction=job['personalized_introduction'],
comment=job['personalized_industry_comment']
)
document.write(f'./Name_Surname_Cover_Letter_{job['company_name']}.docx')
document.close()1. Goes through every dictionary in the list and fills in all the fields with the text from the csv file.
2. Creates a docx file with company name in it and saves it in the specified folder.
The variable names in bold font must be the same as the Merge Field names you have created in your docx template.
You can print the Merge Field names from your template in case you forgot them:
print(document.get_merge_fields())Lastly, we need to convert the docx files to PDF format, and you can convert all files at once by specifying the path to the folder containing docx files:
convert("my_docx_folder/")That’s all!
Don’t forget to check your results before you send them out, and good luck with your job search!