Data Science Academy X FINERY: Clothing Recommender
Project GitHub | LinkedIn: Niki Moritz Hao-Wei Matthew Oren
The skills we demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
ABOUT US
Stella Kim is a data scientist with 4 years of experience using R, with a Master's in Biotechnology and PhD experience in Cancer Biology and Computational Genomics. Proficient in R, Python, and SQL. Passionate about data analytics, visualization, machine learning, statistical methodology, and programming. Interested in helping businesses make data-driven, customer-centric decisions.
Qifan Wang is a recent NYU graduate with MS in Management Information Systems, with previous experiences in business analytics and marketing industry, Qifan is passionate about applying Data Science on the field of business. With 12 weeks of intensive training in the NYC Data Science Bootcamp, he is more confident with handling large datasets and doing machine learning modeling.
Mimi Chung is an aspiring data scientist with experience in the chemical and innovative material science industry as an associate engineer. Previously, she has worked across multiple functions to research, develop and sell conductive materials. She has experience in data analysis, web scraping with Python, data visualization in R, and predictive modeling utilizing several machine learning methods.
Radha Vundavalli is the Director at Cognizant Technology Solutions.
Here is the link to the Shiny application, and here is the link the GitHub where you can find the associated code.
BACKGROUND
For our final capstone project, we partnered with Finery, an up-and-coming women's fashion app which utilizes a user-centric business model in order to provide personalized outfit and style recommendations. Their philosophy lies in the fact that user data can clue us in on specific insights that allow businesses to provide a more streamlined process that is tailored to each customer.
DATA CLEANING, EXPLORATORY DATA ANALYSIS AND FEATURE ENGINEERING
We were provided a set of user data that included item descriptions detailing brands, category of items, and occasions. For our application, we provide the user the option to change the algorithm used for recommendation, brand, item category, and the occasion. Each of these variables were cleaned from an assortment of strings that the data provided.
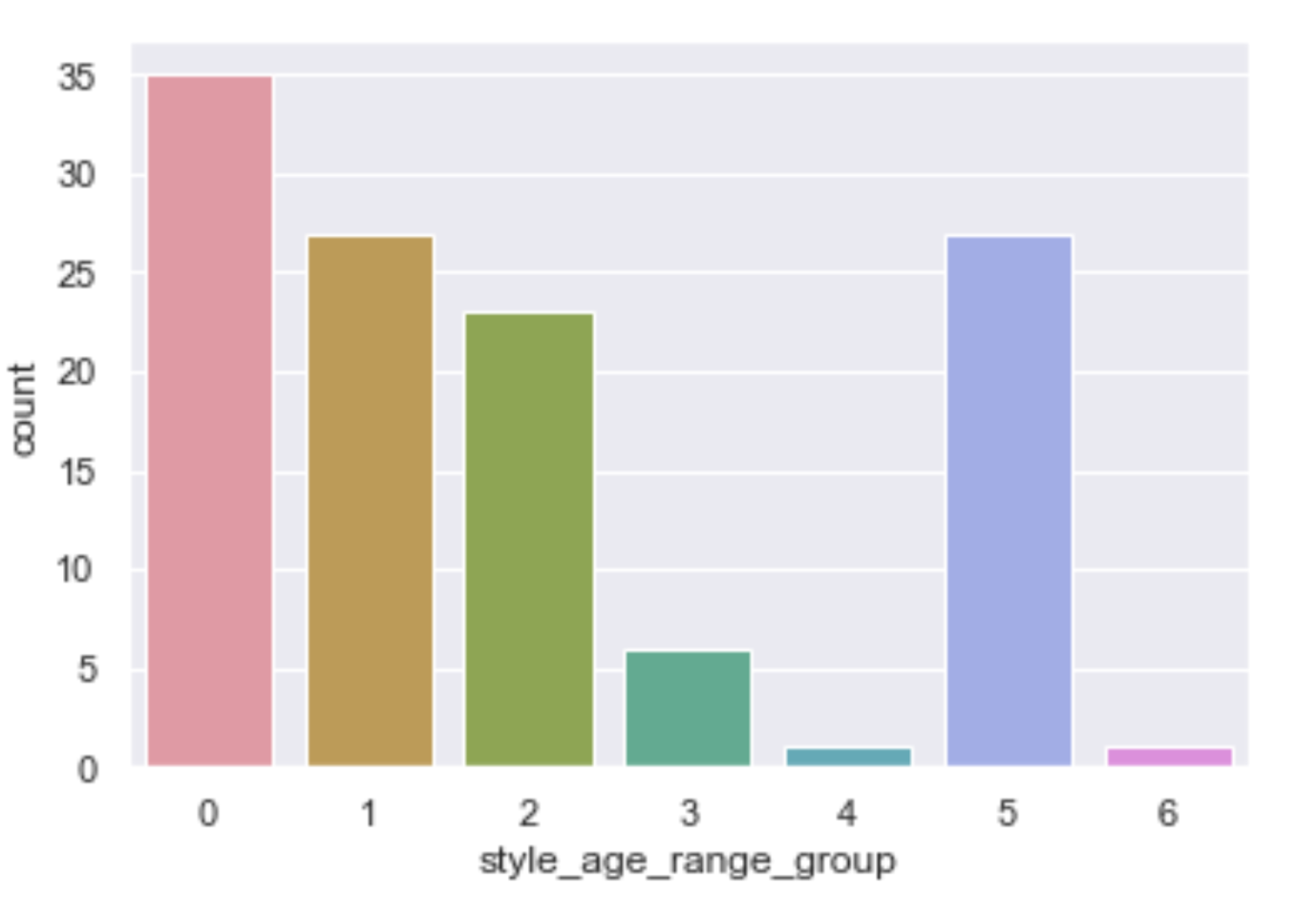
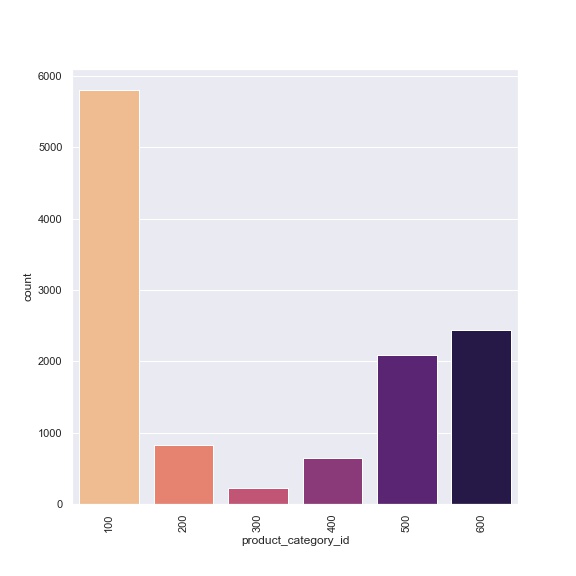
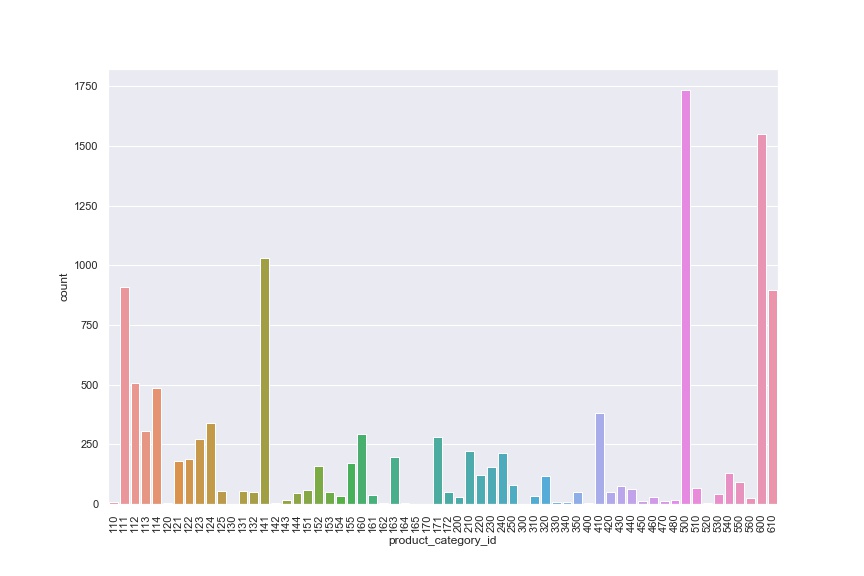
RECOMMENDER SYSTEM
The goal of our project was to create a product recommender system that could integrate descriptive user information, such as age, style preferences, style inspirations (i.e. Instagram models), and behavioral information, such as purchasing history including brand, store, item, and pricing.
We implemented several algorithms in order to try and find the best recommender system. These algorithms include KNNBasic, KNNWithMeans, KNNWithZScore, KNNBaseline, matrix factorization with SVD, SVD++, NMF, and lightFMBasic. The following table, taken from Surprise.io, briefly describes each algorithm.
| random_pred.NormalPredictor | Algorithm predicting a random rating based on the distribution of the training set, which is assumed to be normal. |
| baseline_only.BaselineOnly | Algorithm predicting the baseline estimate for given user and item. |
| knns.KNNBasic | A basic collaborative filtering algorithm. |
| knns.KNNWithMeans | A basic collaborative filtering algorithm, taking into account the mean ratings of each user. |
| knns.KNNWithZScore | A basic collaborative filtering algorithm, taking into account the z-score normalization of each user. |
| knns.KNNBaseline | A basic collaborative filtering algorithm taking into account a baseline rating. |
| matrix_factorization.SVD | The famous SVD algorithm, as popularized by Simon Funk during the Netflix Prize. |
| matrix_factorization.SVDpp | The SVD++ algorithm, an extension of SVD taking into account implicit ratings. |
| matrix_factorization.NMF | A collaborative filtering algorithm based on Non-negative Matrix Factorization. |
| lightFM_basic | Python implementation of a number of popular recommendation algorithms for both implicit and explicit feedback. |
Table 1: Brief descriptions of utilized recommender system algoritms, taken from https://surprise.readthedocs.io/en/stable/prediction_algorithms_package.html
FINERY X NYCDSA
Finally, we were tasked with creating a user interface which showcases our recommender system.
On the menu located on the left (Figure 1), 5 variables are available for further customization of recommendations. These include the User ID, in which we included 5 users, 8 algorithms, as well as numerous brands, categories of clothing, and occasions. Upon selection of any combination of these variables will yield a more narrowed output due to the addition of constraints in each recommendation.
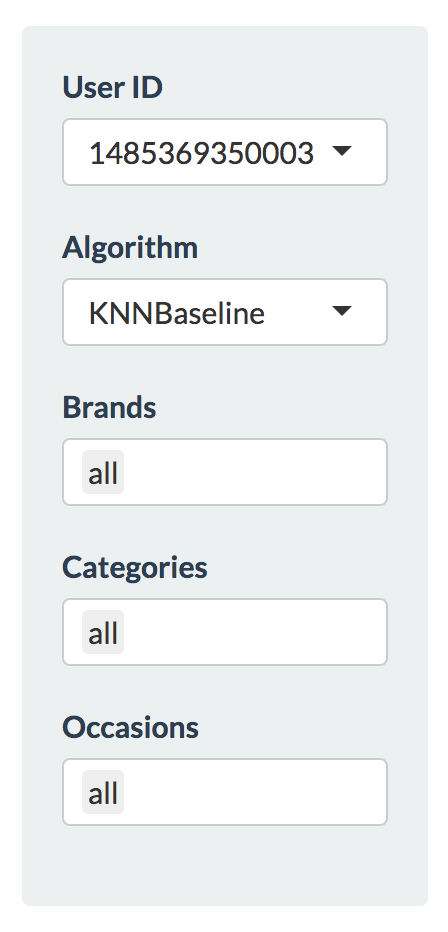
The output is located in the center of the first tab (Figure 2). The output includes the recommended item name, which may or may not already contain the brand name and category in its string. An image is also accompanied with the output and it varies by category.
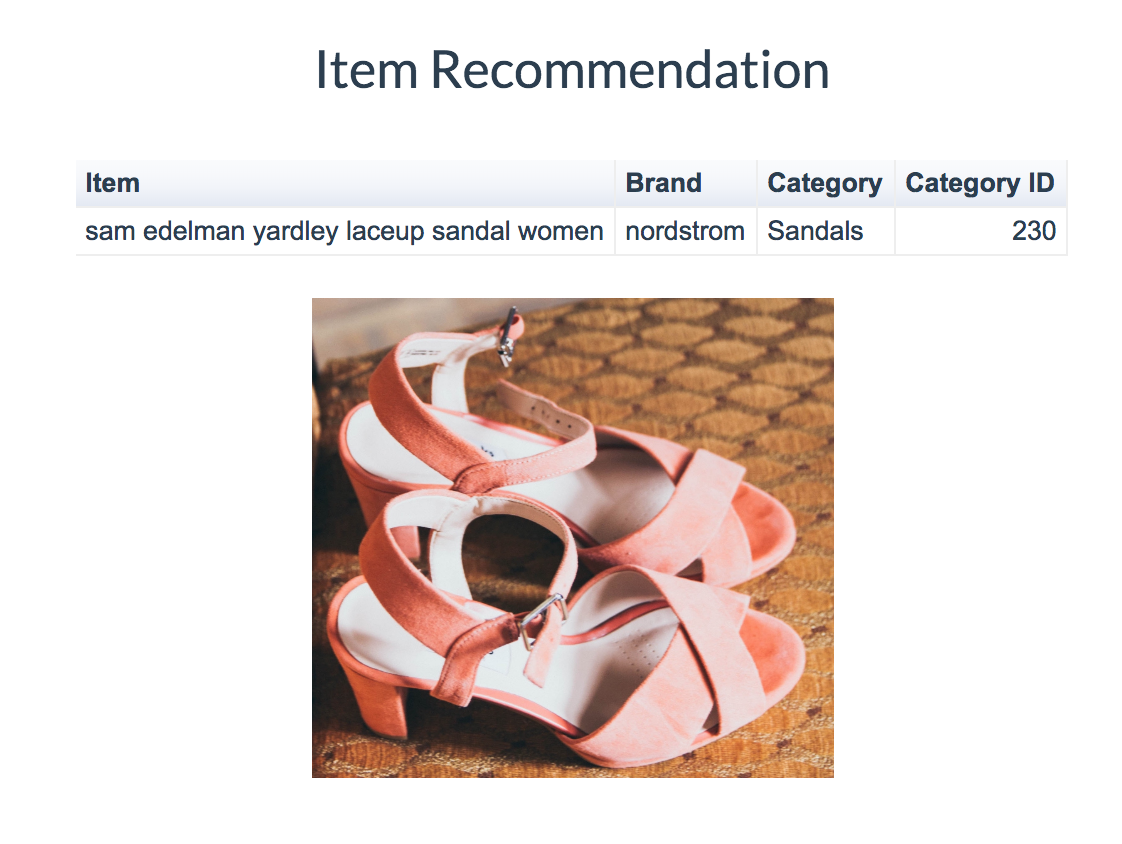
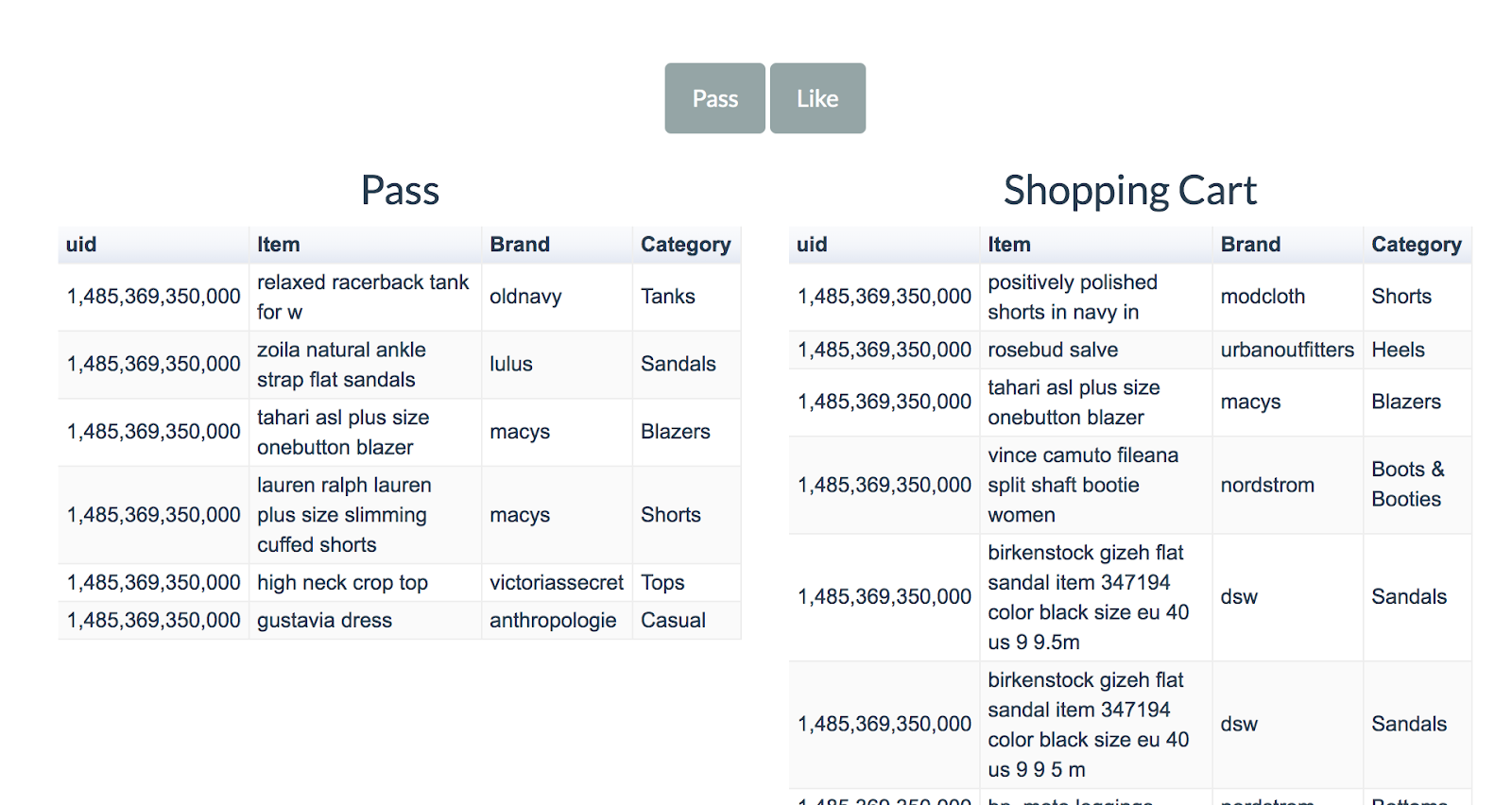
Further customization of recommendations (Figure 3) is available immediately below the output. Here, we provide an option to “Like” or “Pass” the recommended output. Upon “Liking,” the item is appended to the list “Shopping Cart.” Upon “Passing,” the item is appended to a “Pass” list. If an item is appended to the “Pass” list, it is removed from future recommendations.
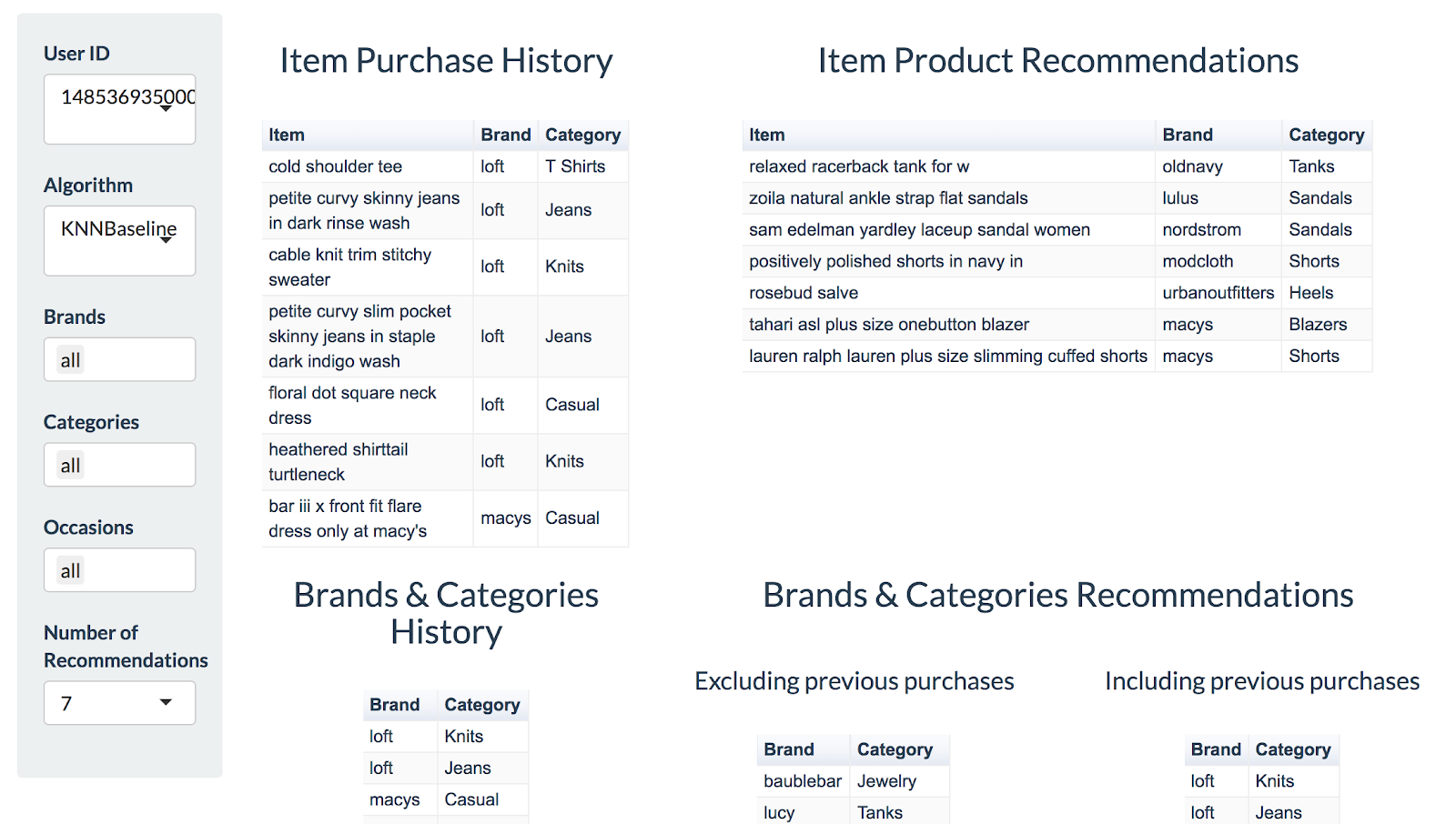
The second tab (Figure 4), “Wardrobe Wizard,” we have a more comprehensive version of our series of recommendations. Here, we include the purchase history of the user, detailing the item name, brand, and category. We also have an output of 7 item recommendations. Finally, we included recommendations that exclude the users’ previous purchases, or excludes previous purchases.
FURTHER STUDY AND DEVELOPMENT
Our goal was to create a basic application that was versatile and buildable. We provided 8 algorithms for choosing, and although there are 4 variables we allowed for customization for each user, the application can become more sophisticated with more variables. The application is buildable.