Data Scraping the Skyscrapers using Scrapy
Contributed by Conred Wang. He is currently in the NYC Data Science Academy 12 week full time Data Science Bootcamp program taking place between September 26th to December 23rd, 2016. This post is based on his third class project - Web Scraping Project (due on the 7th week of the program). |
The skills we demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
Introduction
The Skyscraper Center publishes various types of data and information about the world's skyscrapers.

For example, the 100 Tallest Completed Buildings in the World by Height to Architectural Top :
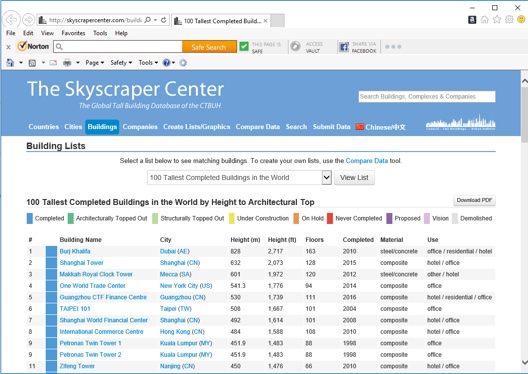
The main page even includes a downloadable PDF. However, some data, like year the skyscrapers were Proposed and Construction Start, is only available in secondary pages:


In order to obtain all the data we needed from the main and all secondary web pages, we used Scrapy.
| An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way. |
.
Data

| ct cc country | ct cc country | ct cc country |
| 21 AE Arab Emirates | 01 AU Australia | 45 CN China |
| 01 GB United Kingdom | 01 KR South Korea | 01 KW Kuwait |
| 03 MY Malaysia | 03 RU Russia | 02 SA Saudi Arabia |
| 02 TH Thailand | 02 TW Taiwan | 17 US USA |
| 01 VN Vietnam |
Statistics about these 100 skyscrapers:
<Usages>
- 40 are multipurpose
- 74 are used for office.
- 43 are used for hotel.
- 29 are used for residential.
- 2 are used for retail.
<Totals>
- 7,758 floors.
- 118,653 feet.
<Time>
- 46 do not have Proposed Year listed.
- 3 do not have Construction Start Year listed.
- From Proposed To Construction Start:
- Cannot compute 46.
- Shortest took 0 year.
- Longest took 9 years.
- From Construction Start To Complete:
- Cannot compute 3.
- Shortest took 1 year.
- Longest took 11 years.
Q : One year to build a skyscraper! Really?
A : No kidding. There are actually 2 skyscrapers:
 |
|

About using Scrapy
Scrapy is really easy and simple.
As depicted in the "A dataflow overview" diagram (below, which can be found at The ITC Prog Blog), we only need to write 3 short Python scripts ("items.py", "pipelines.py" and "skyscraper_spider.py"), and Scrapy did all the data extraction for us from the Skyscraper Center web pages:

We included all 3 Python scripts below.
It is worth to mentioning that:
- "scrapy shell <url>" and Google's Chrome inspect are the two indispensable tools when web scraping with Scrapy.
- Although we love Scrapy, it is not perfect yet. For example, Scrapy will not tell you your Python code indentation is improper.
- With UTF-8 encoding, the str function over text with unicode (for example, "u2026", horizontal ellipsis) will cause an exception. Instead, [<object>.encode('ascii','ignore')] can be used. You can find an example on line 21 of "pipelines.py".
| 1. items.py |
| 2. pipelines.py |
| 3. skyscraper_spider.py |
(end)