Studying Data to Predict housing prices in the Ames, Iowa
The skills the author demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.

Introduction
It’s a challenge to come up with accurate predictions because they require great knowledge in machine learning and lots of practical experience. One recent project on the Kaggle: House Prices, Advanced Regression Techniques allowed competitors to forecast house prices in Iowa, by making a prediction on the basis of machine learning data algorithms.
All the code can be found here:
https://github.com/vickywinter/Predict-House-Price-
Working flow
The working flow the project is list as below. First big part will be data cleaning part, and the second part will be machine learning part.
- Loading Data
- Data Visualization
- Data Cleaning & Engineering
- Model Fitting
- Stacking
- Predicting
Data loading
All the data comes from the Kaggle. There are 1459 test house data and 1460 training house data. Each has 80 features.
Data Visualization
Visualizing the data is a smart way to find relationship that could provide useful insights. Below is a correlation map that shows the 10 features that correlate most with sale price. We can see that features like overall quality and ground living area is highly positive related to the sale price.

We can also clear out outlier by plot the features and sale price. I plot the scatter plot with the continual data and box plot with the categorical data. I removed two outliers that represent an unusually low sale price with high living from the set.


Most continuous data have a linear relationship with the sale price. The categorical data has different relationships with the sale price, but they tend to have a clear difference between each category.
The sale price shows a right skewed distribution that does not quite follow the Gaussian distribution. In order to build an accuracy regression model, the target value should follow a normal distribution, and we can achieve this by take log of the sale price.

Before log

After log
Data Cleaning & Engineering
There are lots of missing data points in the collected data. Most numeric missing features have been filled with median number in its groups or 0. Most categorical missing features have been filled by definition or by most frequent data.
One of the major work in this project is data engineering parts. This process can reduce the model complexity and increase the accuracy. As there are 28 features and almost 3000 data points, it’s necessary to reduce some features and keep only useful data. For example, all the garage information is highly correlated, so only “garage cars” is kept. Other engineering like take log are also applied to the data.
Model Fit
I train the data with four different models:
- Lasso
- Ridge
- Random Forest
- Xgboost
For all the models, it is necessary to find the best hyperparameter to build the best model. I find the best hyperparameter by cross-validation.
Lasso
I used a Lasso Regularization model to fit the train set with all features included. The optimal pruning parameters I got is 0.000193. Below is the performance with this best alpha value.

Ridge
Ridge is another regression model that pushes the coefficient close to 0. The best alpha after cross-validation is 0.1568. The result is a little better for training data but also a little worse for validation data.

Random Forest
Random forest is one of the most widely used models in the world. It allows missing value and categorical data as input.
As there are many parameters to set, we performed RandomizedSerchCV to randomize the selected parameter in a large range, then used the GridSearchCV to cross-validate all the parameter in a smaller range. The best hyperparameter is max_depth=100, max_features=2, min_sample_slipt=2, n_eatimator=600 and so on.

The average error is higher, and it take more time to train the data.
Below is a chart displace the importance of the features. Overall Quality, Ground Living Area and 1st Floor Surface area number is the top 3, which also shows very high correlation with sale price in the above correlation map.

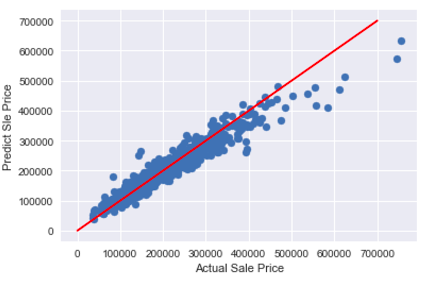
XgBoost
Below is the performance for the XgBoost model. The model is a little better than other models but take longer time.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
The feature importance chart shows the basement unfinished surface, lot area and 1st floor area is the top 3 importance features.

Stacking models
After all the models I have tried above, the final stage arrived. This is the part where I took the results to combine the predictive power of out models. I stacked the four models using the Xgboost model.

MSE for train data is: 0.002076
Above is the result of stacking models
Data Result
Kaggle calculated the score based on the prediction result I submitted. Below is a summary for all the RMSLE:
- Lasso: 0.12153
- Ridge: 0.12966
- Random Forest: 0.17462
- Xgboost: 0.1311
- Stacking model: 0.14029
The Lasso model yielded the best prediction result, and Random Forest had the worst result. Although our training data fit very well for stacking model, it shows high RMSLE in the test data. This may be because the model is overfitted. The result is acceptable for a simple model prediction.
Conclusion
The house price prediction is a good practice to apply machine learning skills. Further analysis can be applied to adopt in more models and better hyperparameter.