An End To End Solution to Reduce Diabetic Patient Hospital Readmissions
Introduction:
- About the Company
Argos Health maximizes claim reimbursement for hospitals, health systems and physician groups by billing & resolving complex claims.
- Project Rationale
The purpose of this project is to develop a predictive model which will help hospitals reduce their readmission rates among diabetic patients.
The hospital has a new 2019 goal of reducing hospital readmission rates. Both the hospital finance and clinical care teams are interested in how the data science team may help these departments reach this goal.
- Technical Approach
Develop a model which predicts whether a patient will be readmitted in <30 days. A new diabetic readmission reduction program intervention will use this model in order to target patients at high risk for readmission. Models will be evaluated on AUC and False Positive Rates.
All code related to this project can be viewed and downloaded from our Github Repository.
We also created a Shiny App so user can easily access and use the tool. Please feel free to try our Shiny web application.
Overview and Public Health Perspective:
Diabetes Mellitus represents a growing public health crisis that costs the United States hundreds of billions of dollars annually. As more baby boomers reach retirement, this burden on the nation’s health system is only projected to rise.
There are two primary categories of diabetes, type 1 and type 2. Both types of diabetes relate to a body’s inability to properly maintain and process the protein insulin. This then limits the body’s ability to properly maintain blood sugar levels. This may result in a number of symptoms, including coma and death. Fortunately, both types of diabetes can be successfully managed through a properly implemented Diabetes Management Program (DMP). A DMP represents the coordination of communication, medication, education, and logistics between a patient, their medical team, and caregivers.
Type 2, or adult onset diabetes, comprises approximately 90% of the diabetes cases within the United States. Type 2 diabetes has risen to this level of prevalence only within the last half-century, and is correlated with many other general indicators of health, including lower socioeconomic indicators, lower levels of exercise and education, and poorer diet. Type 2 diabetes is also highly associated with chronic health risks for heart disease, high blood pressure, stroke, kidney disease, and obesity.
In many cases, proper diet and exercise can improve if not entirely cure the disease. Unfortunately many patients with physical, social, or other challenges experience difficulty in properly maintaining their DMP.
The specific ability to use machine learning in order to predict, at discharge, which diabetic patients would be at risk for a hospital readmission represents a promising application of the discipline. If a diabetic patient is identified as at risk for hospital readmission, a DMP may then be implemented. This will ensure that proper attention is provided to the patient following their discharge, thereby minimizing the chances of a hospital readmission, and ideally improving long-term health habits.
The added expense of providing a properly managed DMP in the time shortly following a hospital discharge comprises the time and expense entailed in the coordination between the physician, discharge nurses, visiting nurses, and social workers. This is estimated to cost in the hundreds of dollars per patient. This expense is minimal when compared to the added expense of a hospital readmission, which can cost well over $10,000 daily, and could easily total 6 figures of expense for a health system.
Even if only a small number of readmissions can be prevented by providing a quality DMP to at-risk patients, a health system can still accrue sizable savings. Even in the case of a false positive (i.e. a patient incorrectly identified to be at risk of readmission) the patient may still experience benefit by incorporating simple health-conscious changes to their lifestyle as a result of their DMP. These long-term changes may well result in improved health outcomes, and reduced health service expenditure.
The discussed project therefore provides a predictive tool for health providers, enabling them to identify patients with the highest risk of being readmitted to a hospital within 30 days of their discharge (30 days being the industry standard for claims reimbursement).
The project’s application has the potential to reduce health expenditures for hundreds if not thousands of dollars per diabetes patient, while simultaneously improving health outcomes, and saving lives.
Background Research:
A number of topics were identified as requiring additional research before fully developing the predictive models into a practical and flexible tool that could be easily applied by a health practitioner to a professional setting. This supportive research fell into two main categories:
- A review of other studies pertaining to the prediction of hospital readmissions
- The gathering of information essential for the estimation of certain parameters entailed within the clinical and practical application of the predictive models
Prior studies were reviewed to see how other researchers have applied machine learning techniques in order to predict the readmission of patients with diabetes, as well as other chronic conditions including heart and kidney disease that are similarly treated with a disease management program.
Some research provided insight for both feature engineering, and the treatment of certain variables within the underlying dataset.
It became apparent that a model’s strength depends greatly on the strength of the data from which it was developed. Other studies reviewed had access to a number of socioeconomic variables which were not present in the available data set. Additional information such as zip code, education level, smoking status, and the availability of a personal-care network could all have been valuable predictors. However they were not present in the data, and therefore could not be included within the model.
In order to meet a health system’s business needs by transferring the model’s predictive power into a specific recommendation for a patient, additional information was needed. Additional financial, clinical, and logistical parameters had to be estimated from literature review.
Examples of such variables include:
- the average cost of hospital readmission
- the average cost of a diabetes management program
- the average success rate of a diabetes management program at preventing a 30-day readmission
The values for these variables tend to vary greatly across health systems depending on a number of distinct and localized factors. The final project and web application accounts for this regional fluctuation by allowing the end user to adjust the values for many inconstant variables. This allows individual health systems to create informed clinical recommendations that are tailored to their own specific needs and situation.
Data Analysis and Machine Learning
The dataset used in this case is a public dataset with 100,000 observations. The dataset can be downloaded here.
- Exploratory Data Analysis
Fifty features including Readmission Status (i.e. the factor being predicted) were included in the original dataset.
- It was determined that the overall readmission rate of the training dataset was unbalanced. The overall readmission rate was 11.346%. This means, if it was predicted that no patients were going to be readmit, this prediction would have a 88.654% accuracy. Therefore, it was decided that a method other than accuracy would be used to evaluate the performance of the model.
The following analysis focuses on optimizing the AUC value, which will be described in more detail in section 3.
- The relationship between each feature and the target feature was observed. Features of note are displayed visually below:
- Readmissions vs. A1C result:


- Readmissions vs. Number of diagnoses:


- Readmissions vs. Days Spent in Hospital:


- Readmissions vs. Number of Lab Procedures:


- Readmissions vs. Number of Medications:


- Readmissions vs. Age Bracket:


- Readmissions vs. Metformin use and Insulin use:


- Readmissions vs. Race:


2. Data cleaning and Feature Engineering
The data contained 50 features, but a number of these needed to either be removed from the analysis or modified for clarity before applying them into our model. Notably, the data included a “Weight” feature to denote patient weight. This would theoretically be a relevant feature for the analysis, but unfortunately, weight was only measured in approximately 3% of observations. It was therefore decided to exclude it from the analysis. The variable “Payer Code”, which corresponded to the payer used for the patient’s insurance, was absent from over 40% of observations. As this variable did not have any clear relevance to our model, it was omitted. Modified “coded” features were created by aggregating related hospital diagnostic codes that were provided in the data, into a finite number of overarching categories such as “stroke” or “heart disease”. Combining similar codes into aggregate diagnostic categories provided greater clarity and interpretability for the model, and improved the predictive results.
The dataset additionally included 24 features that corresponded to different potential diabetes medications that a patient may have been taking. In each medication-specific feature, values were set to either “No”, meaning the patient was not taking that medication, or “Up”, “Steady”, or “Down”, which meant the patient was taking that medication and their dosage was either increased, kept steady, or decreased. A number of different possibilities were explored to simplifying this data and improve the model. By using train/test validation it was determined that converting “Up”, “Steady”, and “Down” to “Yes” (indicating that the patient was simply taking the medication) yielded the optimal results. To compensate for this, a new new feature was added to indicate whether the patient experienced any change in dosage (“Up” or “Down”) for any medication.
3. Modeling
After feature engineering came the process of developing a predictive model. A preferred metric to optimize had to be selected for the model. The objective was to predict whether or not a given patient would be readmitted to the hospital within 30 days. In the data, this was true of approximately 10% of patients. Because of the considerable imbalance in outcomes, accuracy is not the ideal metric to use. For highly imbalanced classification outcomes, the highest accuracy is often achieved by the model simply guessing the more likely outcome for every observation, which in this case would yield an accuracy of 90%, but would have no predictive value. Instead, for imbalanced classification problems, it is often preferred to judge model performance by scoring the predicted probabilities of the model. A number of metrics can be used to measure predicted probabilities, including F1 Score, Briar Score, and Area Under the Curve (AUC). We settled on AUC as our metric of choice as it is commonly employed in the healthcare industry for classification scoring.
There was also an intermediate group of patients who were readmitted to the hospital, but after 30 days had passed. In the classification problem, these are technically negative values, but their existence in the dataset offered some additional information to the model. Approximately 4% of values from this group whose characteristics (in a simple linear regression) closely matched those from the positive group (who were readmitted within 30 days) were removed. This increased the metrics for our model in validation with a test data set.
A stacked model was developed through building from three distinct machine learning algorithms (logistic regression, random forest, and XGBoost). For each model, K-Fold validation was used to determine optimal algorithm parameters. The AUC for the logistic regression model was 0.668, the AUC for the random forest model was 0.671, and the AUC for the XGBoost model was 0.680. Grid-searched linear combinations of percentages was used to stack these models together and settled on an optimal combination of 56% XGB, 23% Random Forest, and 21% logistic regression. Using this stacking combination, a final AUC of 0.684 was achieved.
4. Result
| Confusion Matrix and Statistics | ||
| Reference | ||
| Prediction | 0 | 1 |
| 0 | 17646 | 2179 |
| 1 | 113 | 92 |
| Accuracy: | 0.8859 |
| 95% CI: | (0.8811, 0.8899) |
| No Information Rate: | 0.8866 |
| P-Value [Acc > NIR]: | 0.6849 |
| Kappa | 0.0566 |
| Mcnemar's Test P-Value: | <2e-16 |
| Sensitivity: | 0.040511 |
| Specificity: | 0.993637 |
| Pos Pred Value: | 0.448780 |
| Neg Pred Value: | 0.890088 |
| Prevalence: | 0.113380 |
| Detection Rate: | 0.004593 |
| Detection Prevalence: | 0.010235 |
| Balanced Accuracy: | 0.517074 |
| 'Positive' Class : | 1 |
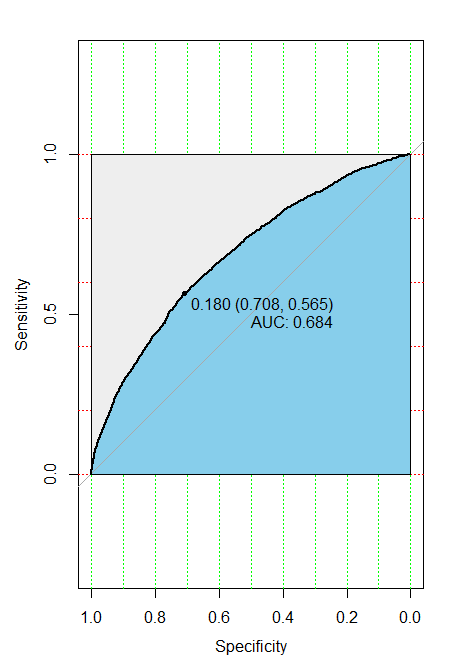
ROC Curve Plot
Interaction:
The Prediction Visuals tab of our Shiny application allows the user to explore the importance of each feature included in the predictive model. Dynamic pie plots illustrate readmission ratios and relative contribution of each feature to readmission.

Dynamic Pie Plots Illustrating Readmission Ratios for Select Variables (top) and Relative Variable Contribution to Readmission (bottom)
The Feature Importance tab includes a static plot of the top 20 features in the model and their relative importance to predicting patient readmission. With this information on hand, the user is aware of the impact that each feature has on patient readmission.

Top 20 Features that Impact Patient Readmission
The User Options tab allows an individual to explore specific features such as gender, race, age group, minimum time in the hospital (days) and the minimum number of procedures during that stay. A dynamic pie chart shows the readmission ratio of patients with statistics set by the user.
The Readmission Variables tab allows the user to select from the different features included in the model and see for themselves the relative importance of each feature. It is important to note that this pie plot only shows the relative importance among the features selected by the user.


Interactive Tabs that Take In User Input


The patient table allows individuals to search through the dataset after predictions were made.

On the table, information provide is the basic information of the patient. The encounter ID, Patient Number, Age, Race, And Gender of the individual are all provided. If you wish to search through the data it as simple as typing into the search bar above the table.

Upon typing into the search bar, the table refreshes itself and provides the user with patients that match the characteristic provided. In the example above, an encounter ID was provided. Because Encounter IDs are unique, the table subsets until only that individual is remaining
This allows health care and insurance providers to quickly look for individuals and their health information. From here, all it takes is to click on the row you wish.

On the right side of the Patient Table page, the user can get an in-depth look at the patient selected. The first tab, patient demographics, gives the user the information already provided on the main table. The big difference is the displayed prediction for this individual. For the patient displayed above, the patient was not predicted to be readmitted.

The second tab gives the information taken when the patient was admitted to the hospital. It can be seen that this person was admitted in the emergency room, stayed 5 days in the hospital and was discharged to have healthcare at home. The user can also identify for each patient the number of inpatient visits, outpatient visits, and emergency visits by the patient in the prior year.

Finally, on the Diagnoses/Test Results tab, the user can get information about why the patient came to the hospital and if any diabetic related tests were administered. It can be seen that the patient’s primary diagnosis involved respiratory issues, but was also diagnosed with metabolic and neoplasm issues. In the case of this individual, the A1C and Glucose tests were not administered.
Financial Modeling:
With a strong prediction model in hand, it became necessary to apply this model in order to determine how much a health service payer (i.e. a private insurer, Medicare or Medicaid, or an uninsured individual) could save through application to optimally allocate diabetes management plan (DMP) resources.
Below is the template used for the basic finance equation:
Total Savings = [(the cost of readmission per patient) * (the count of true positives) * (the percentage of readmissions prevented by implementing a DMP)] - [the cost of a diabetes management plan * [(the count of true positives) + (the count of false positives)] ]
This equation can be interpreted as the difference between:
- the money saved for each prevented hospitalization, and
- the added expense of enrolling every identified “at-risk” patient into a DMP
Many of the numbers used to derive these savings are estimates obtained from literature review. Actual values are likely vary, depending on a number of factors including geography and underlying differences across patient populations and medical staff.
The accompanying Shiny web application accounts for this variation by enabling the selection from a range of values for these in-constant variables. This app enables financial predictions to be tailored so that they may meet a variety of nuanced situations within various different health care environments.
Examples of the values that may be specified through the app include:
- The 30-day hospital readmissions rate for diabetic patients
- The daily cost for a hospital stay
- The success rate of the DMP
The expense per hospital readmission is quite high for the healthcare payer. Based on literature review, it was estimated that the average daily cost of hospital care fluctuates around $10,000. Based on the population within the dataset, the average length of a hospital stay was calculated to be at 4.5 days. Therefore the estimated savings for each prevented readmission was calculated to be approximately $45,000.
It is important to note that simply because an at risk individual receives a DMP, it is not guaranteed that they will avoid readmission. Even with perfect execution, it is possible that a comorbidity, such as heart or liver disease, or any number of external factors may still result in a readmission. The estimated success rate of the diabetes management program hovered around 39-50%. Therefore as explained above, the savings from prevented readmissions is calculated as the product of:
- the per patient expense of readmission
- the number of true positive patients both identified and enrolled within a DMP
- The success rate of the DMP at preventing a readmission for a patient
Implementing the DMP requires an upfront expenditure on the part of the healthcare payer. This expenditure is subtracted from the savings realized through reduced readmissions. The cost of the DMP is based on the time of the physician, discharge nurse, and home visiting nurse, and was estimated to be $500 per patient based on literature review.
However, not every predicted readmission is accurate. A number of false positives are also identified, and are likewise enrolled within the diabetes management. The upfront expenditure for the plan must be applied to both the true, and false positive predictions of the model.
Therefore total up front expenditure for implementing the readmissions is determined by the cost of the DMP, multiplied by the sum of the true and false positives.
Project Delivery Pipeline:
The project was completed with the development of an end-to-end solution using the Python package Flask. In this application, one is able to input a csv file with the patient information. After uploading the csv file from one’s computer and clicking the “Submit” button, the Flask application outputs a csv file with predictions of whether each patient will be readmitted to the hospital under 30 days and the probability of each patient being readmitted under 30 days. The outputted csv contains all the columns that were in the input csv file but has two extra columns: one with predictions and one with probabilities. The prediction column would either have 0 or 1. If the column contains a 0, the model predicts that the corresponding patient will not be readmitted within 30 days. If the column contains a 1, then we are predicting that the patient will be readmitted within 30 days. The probability column contains the probability that the corresponding patient will be readmitted.
The Flask application is pre-loaded with the trained model. The model is stacked with three separate models: an XGBoost model, a logistic regression model, and a random forest model. When a csv file is inputted into the Flask application, the data is run against the stacked model. The prediction depends on the probability of the patient being readmitted under 30 days. The current application predicts that the patient will be readmitted if the probability is greater than 0.5. However, the Flask application has the potential to update the threshold that determines if the patient will be readmitted and needs the plan described above.
As detailed above, the outputted csv file includes a column with the prediction for each patient. If the patient has a 1 in this column, i.e., if we predict that the patient would be readmitted within 30 days, then we plan to give the patient the plan we described above.
-----
References and Links:
Beata Strack, Jonathan P. DeShazo, Chris Gennings, Juan L. Olmo, Sebastian Ventura, Krzysztof J. Cios, and John N. Clore, “Impact of HbA1c Measurement on Hospital Readmission Rates: Analysis of 70,000 Clinical Database Patient Records,” BioMed Research International, vol. 2014, Article ID 781670, 11 pages, 2014. Link
Data Set Repository: Link
Github Repository: Link
Shiny App: Link