Bootcamps
Bootcamps
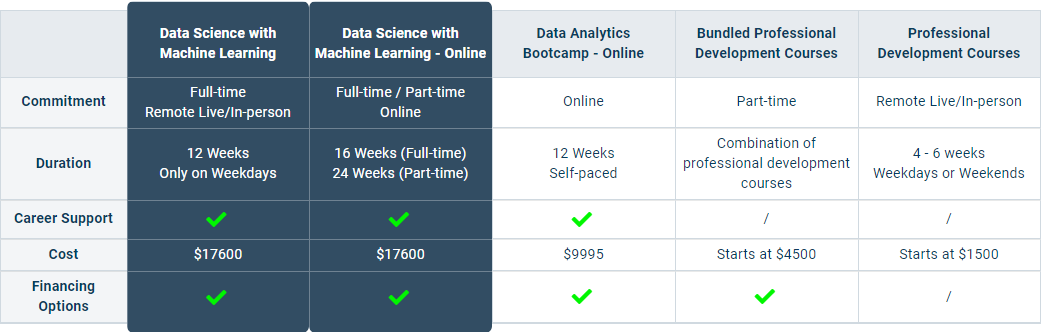
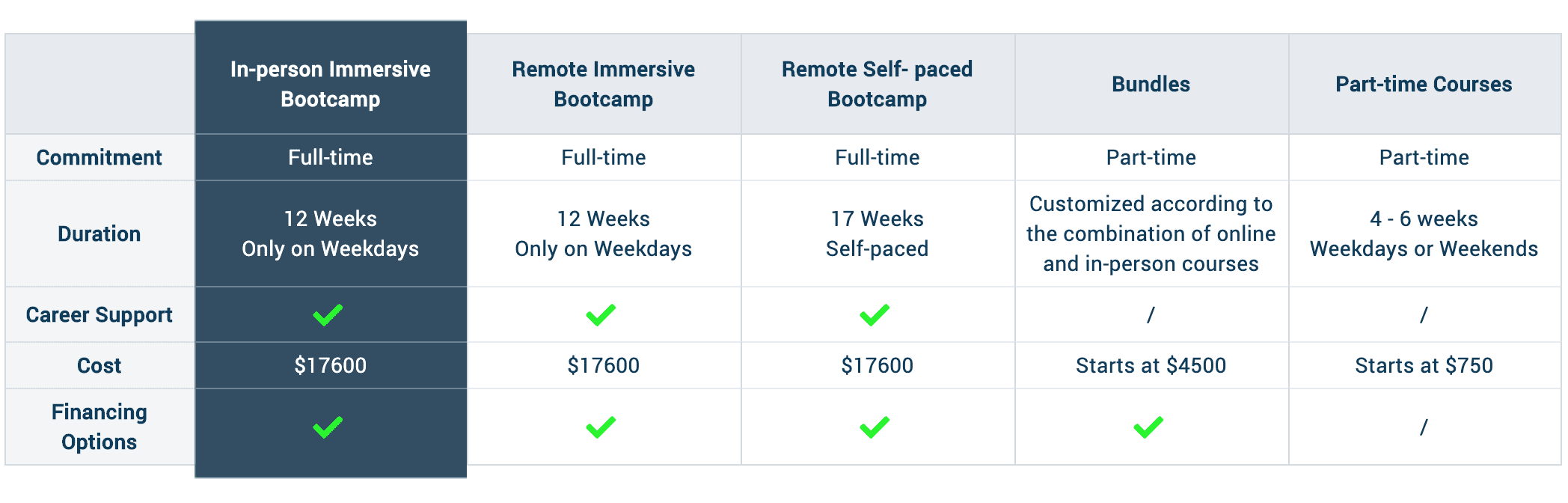
Data Science with Machine Learning Flagship 🏆
Data Analytics Bootcamp
Free Lesson
Intro to Data Science New Release 🎉
Find Inspiration
Find Alumni with Similar Background
Courses
View Bundled Courses
Bootcamp Prep Popular 🔥
Data Science Mastery
Data Science Launchpad with Python
View AI Courses
Generative AI for Everyone New 🎉
Generative AI for Finance New 🎉
Generative AI for Marketing New 🎉
Bundle Up
Learn More and Save More
Combination of data science courses.
View Data Science Courses
Beginner
Introductory Python
Intermediate
Data Science Python: Data Analysis and Visualization Popular 🔥
Data Science R: Data Analysis and Visualization
Advanced
Data Science Python: Machine Learning Popular 🔥
Data Science R: Machine Learning
Designing and Implementing Production MLOps New 🎉
Natural Language Processing for Production (NLP) New 🎉
For Companies
Tutorials
Bootcamps
Courses
Students Work
About
Bootcamps
Bootcamps
Free Lessons
Find Inspiration
Job Outlook
Alumni
Courses
Bundles
financing available
View AI Courses
View Data Science Courses
Beginner
Intermediate
Advanced