Data Driven Investment: Lasso Regression Pipeline for Real Estate Investment
The skills we demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
Introduction
I do not know about you, but I love watching HGTV at night. The romanticism of taking that decrepit old house with the hilariously droll finishes and transforming it into an aesthetic and beautiful work of art seems to only exist in a Property Brothers episode. To the contrary, real estate investment is becoming more informed and data driven, making investors sweat from the rise in competition. Investment firm adaptation to the surge in AI driven decision making is crucial to remaining viable in the increasingly agile modern market.
If you are a student or instructor of data science, you are likely familiar with the infamous Kaggle competition, “House Prices - Advanced Regression Techniques.” The purpose of this competition is to engineer features and deploy a sale price predictive model, using the root mean squared error metric for model performance. The analysis detailed in this report will use the Ames Housing Market dataset to make informed decisions about the investment climate of Ames, IA in 2010 through the development of an optimized lasso regression pipeline for descriptive analysis.
Evaluation of Missingness and Data Cleaning
Figure 1 is the missingness matrix of the Ames real estate data set. It is apparent that a few columns are very sparse and may not be a viable feature for modeling and that a majority of variables share a pattern of missingness, indicating an interdependence. However, there are variables within these groups with missing data without observed missingness in corresponding variables.
In the data description (available in the Appendix section), there are certain variables where “NaN” represents the absence of a given feature. For categorical or ordinal variables, “None” was imputed, while numerical variables were imputed with 0 values. Iterative imputation is discussed in the machine learning pipeline implementation section.
Exploratory Data Analysis
The Sale Price and Square Footage Relationship
Figure 2 shows the relationship between the sale price and living area square footage, which only contains the first floor and second floor if applicable. It is apparent that there is a high degree of heteroskedasticity that violates the constant variance assumption of linear regression.
Applying a log scale transformation removes the fin like shape and decreases the covariance of the variables. This illuminates one of the most important relationships in the development of a descriptive multiple linear regression model; price per square feet of living area. Further exploratory data analysis will be centered around the analysis of potential features versus price per square feet. There are still outliers present that can be accounted for using Sci-Kit Learn’s RobustScaler.
The Price and Square Footage Data Trade Off
Intuitively, larger homes are going to have larger sale prices. Generally, aside from a few outliers, there is a slight upward slope between first floor square footage and price per square feet in Figure 4.
The relationship between second floor square footage and price per square feet tells a different story. As the amount of square footage increases, there is virtually no upward slope. This suggests that two-story houses would be an unfavorable investment in the Ames market, but why?
This likely has to do with the average consumer in Ames, IA being a college student. Ames, IA is home to Iowa State University (ISU) and faculty members seeking more family friendly living environments will seek larger square footage homes far away from the college party scene. This makes investment properties in Ames heavily targeted towards student rentals. The lower demand for high square footage two story houses likely drives the price per square foot down.
Basement Feature Data Analysis
Ames is located on the Great Plains in the middle of tornado alley. So aside from the additional square footage, basements have a lot of utility to the area consumer. In Figure 6, there is a clear large positive slope between price per square foot and basement square footage after a log(x+1) transformation. There is still an easily observed decrease in the covariance with increasing square footage, yielding a fin-like shape. This does not necessarily exclude basement square footage as a significant feature, but it is evident that further preprocessing is a necessity.
Despite the obvious positive slope, all basements are not created equal. Some basements are a barren landscape like you would see in a low budget B horror film, while others have the quality of a secondary living space, home theater, or recreational area. Of course, you are limited with your available options based on the ceiling clearance of your basement.
Basement Quality Data Analysis
Figure 7 shows the distribution of basement quality, which is a measure of basement height. Basements with a height of 80+ inches have a significantly higher income than basements with lower clearance, but the biggest increase in median price per square feet comes from clearances of 100+ inches. This makes intuitive sense because using the basement as a secondary living/recreational requires the clearance to be sufficiently high to not make people claustrophobic.
Figure 8 delves deeper into the degree of basement quality in regards to livability. The different categories are clearly not linear, so generating polynomial features will be a necessity. An interesting observation is that the median price per square feet are similar for unfinished, below average living quarters, and average recreation room. Below average living quarters has the highest median price per square feet among the three features. Which is reasonable because it provides the potential for more rental tenants as opposed to simply using the space as a game or fitness room.
Figure 9 shows the price per square footage distribution for basement exposures. The term basement exposure refers to the walkout area outside of the basement as shown in the picture below.

There is a very distinct difference in median price per square feet between the various categories of basement exposure. Basement exposures classified as average and above typically contain split levels or foyers. These areas can serve as additional space for entertaining or fulfill a functional purpose such as a garden or outdoor kitchen. It makes sense that these exposure classifications would have such a large leap in median price per square footage.
Garage Feature Analysis
The garage is more than just a place to store your vehicles. The amount of functional diversity that a garage provides is a significant contributor towards the overall price per square feet of the house. Figure 10 shows the price per square feet distributions of different garage types. It is evident that attached garages have the highest median price per square footage. This may be due to the convenience of being able to park your vehicle, close the garage door, and walk into the house.
Basement and built-in style garages have similar median values and are both easily accessible to the house. The difference between the built-in and attached styles is that the built-in type is typically associated with being fully integrated into the house and typically contains a room above it. The built-in style is associated mainly with two-story houses, so as was discussed earlier, the price per square footage decrease is consistent.
Figure 11 shows the distribution of garage quality category distributions. There is a distinct jump in the median price per square feet between fair and typical average qualities. The medians of typical average and good quality garages are relatively similar, while there is a significant jump in the median of excellent quality garages, but the distribution size of excellent quality garages is significantly smaller than the other category distributions.
Figure 12 shows the relationship between price per square footage and garage square footage after a log(x + 1) transformation. There is a clear positive slope and despite some outliers, the covariance appears to be near constant. It is evident that this feature would benefit from RobustScaler transformation.
Fireplace Feature Analysis
The Midwestern states are known for their formidable winters. It is important to have a fireplace as a functional piece, but the aesthetic of the masonry work is also extremely important. Figure 13 shows the price per square footage distribution of fireplace quality ordinal categories. It is apparent that an excellent quality fireplace with finely crafted masonry details has a significant contribution towards the median price per square footage. What is interesting is that a good quality fireplace does not appear to differ in median price per square footage in homes with a poor quality or no fireplace.
While the quality of the masonry of the fireplace has a significant effect on the median price per square feet, the number of fireplaces in the house does not appear to affect the median by much.
Kitchen Feature Analysis
The kitchen is where all the action happens, in my humble opinion. Going from cooking in a cramped galley kitchen to an open kitchen with modern appliances, a beautiful backsplash, and breath-taking finishes, you never want to revert back to the former.
Figure 15 shows the price per square footage distribution of homes with different kitchen qualities. It is apparent that homes with an excellent quality kitchen have a higher median price per square footage compared to other quality categories.
Machine Learning Pipeline Implementation
This dataset has 81 variables, so I will not bore you any further with exploratory data analysis. The exploratory data analysis shown above highlights some key points for the development of the descriptive Lasso model. Moving forward, we will shift gears towards the implementation of the descriptive model and some of the key insights extracted. (Pardon the 70's font.)
Data Preprocessing
Prior to insertion into the Lasso regression pipeline, ordinal variables were converted into an integer ranking system through SKLearn's OrdinalEncoder. Categorical variables were dummified using the get_dummies function in Pandas. The target variable, sale price, was converted to a log base 10 scale. Continuous features were converted to log base 10 scale. OverallQual and OverallCond were removed to reduce multicollinearity with more specific feature quality and condition indicators.
Feature Engineering
Several distance features were engineered based on cosine distance. The features are the following;
- Airport Distance
- ISU DIstance
- Downtown Distance
A new variable, HouseAge, was created that was the summation of total square footage variables. House age, remodel age, and an ordinal remodeled feature were also generated.
Model Selection Data Rationale
Largely, Kaggle competitions are about model performance and the minimization of a cost function, such as root mean squared error. Predictive modeling is a powerful skill to have.
However, a great mentor once told me that all great projects are based on the insights that are extracted and a business function that is improved. It is with this rationale that I have selected Lasso regression to describe this dataset. I could select XGBoost or Random Forest and get superior accuracy due to the combination of ensemble/bagging and stochastic gradient boosting. Which are due to the non-linearity of the data, but this does not align with the ultimate goal of this project.
Lasso is one form of penalized regression. Lasso applies L1 penalization to mitigate the effects of overfitting and multicollinearity to produce what is known as a sparse model with minimal parameters. A more sparse regression model simplifies the interpretability of a descriptive model. The L1 penalization term, also known as the alpha term, penalizes the sum of absolute error to shrink feature beta coefficients to zero as alpha approaches infinity. Equation 1 shows the lasso cost function. Simply put, this shows that the ultimate goal of lasso is to minimize the absolute sum of squares.
Iterative Imputer Tuning
Performance of the iterative imputer was assessed using 3-fold cross validation using the following parameters;

The alpha value was fixed to 1e-4.
Lasso performance across imputation method and strategy appears to have negligible variations in the metric for model scoring.
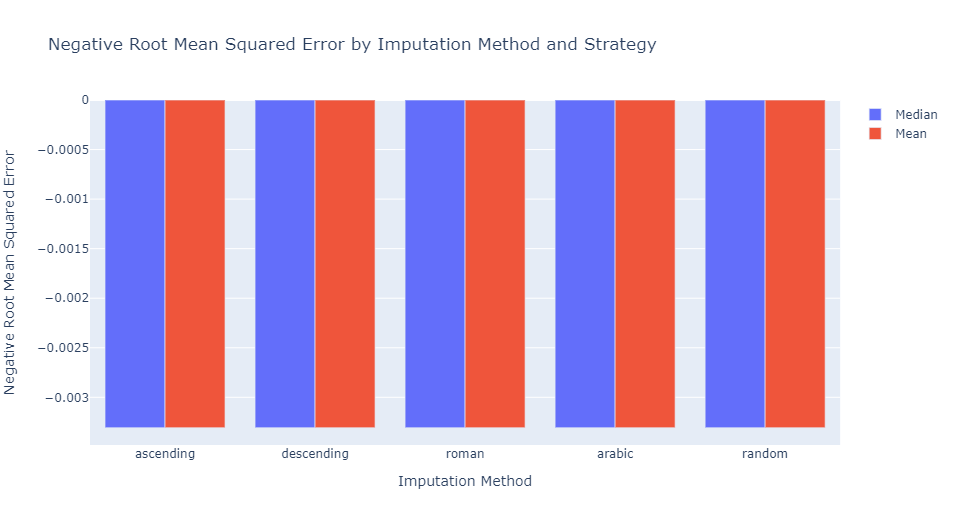
Despite other methods having a marginally better scoring performance, random imputation has comparable accuracy with less computational expense. The computational expense is reduced further by performing median imputation as opposed to mean imputation.
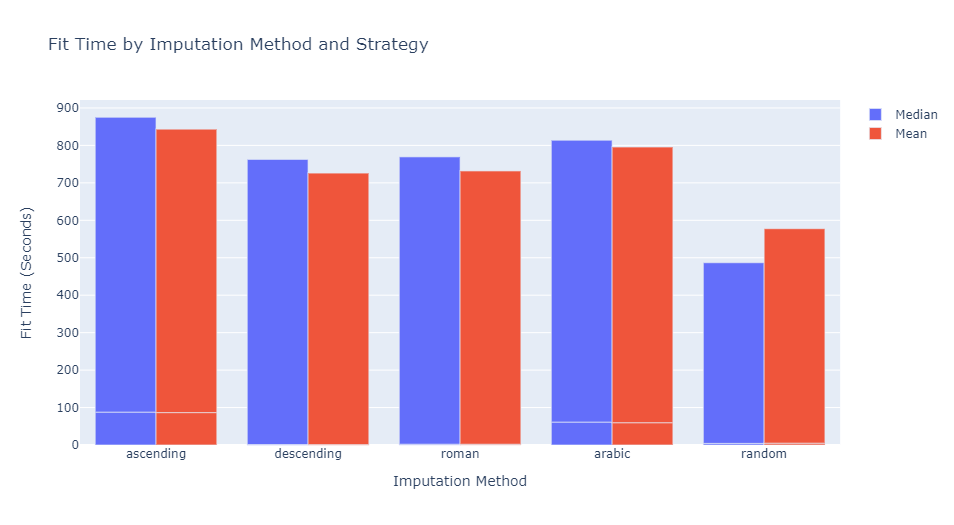
For the negligible loss in performance and lesser computational cost, random iteration with the following parameters will be used to grid search lasso hyperparameters.

Lasso Hyperparameter Tuning
The first method of hyperparameter tuning is alpha tuning by 3-fold RandomizedSearchCV. The random search parameters are listed below;

Figure 16 shows the 3-fold randomized search cross validation mean negative absolute error results from an alpha range of 1e-12 to 0.1. The results from 1e-12 to 2e-3 appear to be stable but then experience a linear decrease until plateauing around 0.1.
Using randomized search cross validation has decreased the alpha iteration range for a more refined grid search cross validation with additional tuning parameters. Multiple grid searches were performed and resulted in this final optimized model. The iterative parameters are shown below;

Figure 17 shows the result of the grid search cross validation.
The optimized Lasso regression has the following parameters from 3-fold grid search cross validation shown below;
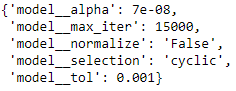
This combination of parameters yields a mean negative absolute error of -0.04 with an r-squared of 89.25%.
Residual Distribution Data
Figure 18 shows log and standardized residuals plots. It is apparent that log transformation of the SalePrice variable yielded a model with a gaussian residual distribution relative to a non-transformed target variable. The non-transformed target variable exhibits clear heteroskedasticity and a positive bias. The 95% confidence interval error band increases at higher sale price values, but does not grow unreasonably large. This model is relatively simple, but the standardized residual output may suggest that interaction terms and polynomial features may help in outlier prediction.
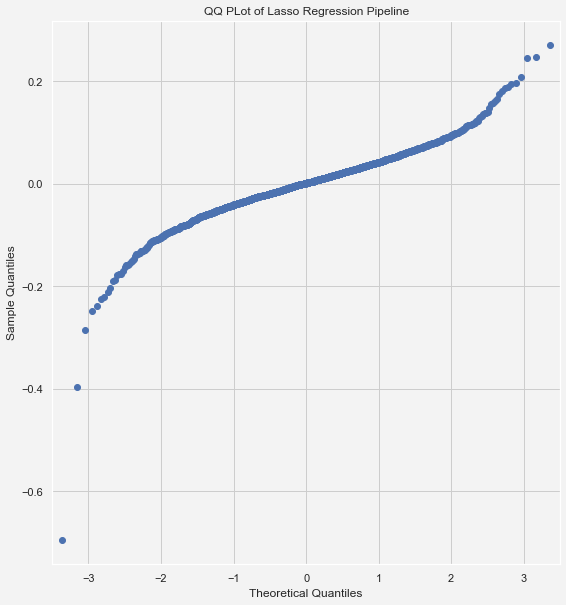
The QQplot of the residual distribution quantiles further corroborates that the normality assumption of the residual distribution is accurate.
Lasso Best Estimator Results and Beta Interpretation
A log scale dependent variable makes the interpretability of the beta coefficients more challenging. However, there are methods to convert the beta coefficients where meaningful insight can be extracted. The following equations outline the steps involved in gaining insights into the raw lasso coefficients.
One important aspect that was observed during EDA was the price and square footage trade off. The raw coefficients show that with increasing square footage, the sale price increases. However, to maximize return on investment, the main relationship that needs to be measured is price per square feet. The following manipulations outline how this is achieved:

The resulting 𝛽 - 1 term is -0.957, corroborating the observation of increasing 2nd floor square footage decreasing price per square feet.
Exponentiating both terms by 10 converts the original additive model into a multiplicative model. Dividing the multiplicative model by HouseArea subtracts 1 from the beta value, making the model a measure of price per square footage.
The interpretation of continuous variables is that beta is equal to the percent change in y when the continuous variable increases by 1%;

Non-Binary Variables
Categorical variables that are binary are not log transformed, but the typical interpretation of categorical variables being the difference between the mean target variable value between the binary classes is not applicable in this case. The exponentiated beta is interpreted as the ratio of the means of the target variable of the “1” category to the “0” category.

Ordinal variables are represented as standard numerical variables. The beta is exponentiated and subtracted by 1. This formula represents the percent change in y per unit increase in x.

Figure 19 shows the contribution of ordinal features in the price per square footage per unit increase. It is then followed by a table that provides a summary of the graph as well as calculated results for differences in ordinal values.
Functional Features and Prices
It is apparent that functional features are large contributors to price. While central air has the highest effect on target variable percent change, it is important to point out that it is a binary ordinal variable, but still outperforms other features with more categories. The functionality of a home, which is the extent of deductions found during inspection, has a very positive factor in the target factor.
A house with the highest functionality compared to one with mild deductions increases the target variable by approximately 7.2%. Some of the more interesting findings involve the negative impact on price per square foot of features like kitchen quality and external quality. Houses that would be more desirable to skilled workers, such as professors, possess high quality features, but it is apparent that the market is mostly lower end internal quality finishes.

Figure 20 shows the continuous feature contribution towards the target variable per 1% increase in feature variable. Intuitively, the largest contributor to the overall square footage of the house is the above ground living area. The finished livable basement square footage and lot area also positively affect price per square feet. Intuitively, the age of the house and remodel adversely affect the target variable. Total basement square footage, garage area, and low quality basement square footage adversely affect the target variable.
Though slight, distance from Iowa State has a positive contribution towards the target variable, while airport distance is detrimental. This may be a hint of multicollinearity and may warrant a future investigation of Elastic Net for combined L1 and L2 penalization.
Neighborhood Comparisons
Figure 21 shows the ratio of the mean price per square foot of each neighborhood relative to other neighborhoods. Green Hill exceeds other neighborhoods by 66.32%, however it is important to point out that it has very little observations, so this estimate is likely very flawed. Neighborhood based modeling may be improved by creating neighborhood features through support vector clustering or KNN of latitude and longitude coordinates to mitigate inaccuracy associated with sparse neighborhood data.
It is possible that some neighborhoods may be mislabeled and coordinate clustering can provide a more accurate result. For this reason, I decided to drop the neighborhood column, so all betas being presented are unaffected by this. This is purely a demonstration of the need for descriptive enhancement.
Data Regarding Categorical Features
There are a substantial amount of categorical features, so focus will be aimed at the most substantial features. Figure 22 shows the categorical features with the highest mean percent increase relative to other options in the same category and the highest categorical variable is precast exterior. Precast exterior is a common material of construction on high end contemporary houses as shown below. Unsurprisingly, this style of exterior is 42.46% higher on average than other exterior styles.

Low density residential zoning has the highest positive ratio followed by high density. In general, residential zones have higher cost than commercial or agricultural zones. Membrane roofs, which are a flat style roof common on ranch style houses, have the highest ratio of 26.33%. This suggests that ranch style homes are highly desirable in this market. Wood shingle roofs are very common on older style homes, such as colonials or Victorian style houses.
Data Regarding Internal Features
The internal features of these houses may not be as updated, but they have powerful curb appeal for consumers seeking rustic charm. More features that indicate the prevalence of Victorian and colonial houses are stone foundation and brick face exterior. Brick face exteriors are common on colonial and ranch style homes, along with more modern suburban style houses. One cannot neglect the power of “location, location, location.” Houses in Ames with an off-site positive feature nearby, such as school, shopping, or work, have on average 20.46% higher price per square footage.
Stone foundations are prevalent in old homes and are often a center for attention as far as home inspection goes. Stone foundations are synonymous with cracked or damaged foundations. While the rustic charm carries its appeal, the obvious detriments of an older home can come with considerable cost. It is important to note that these categorical variables are only accounting for sale price with all other variables held constant.
Feature With Highest Detriment
Figure 23 shows the feature proportions with the highest detriment towards price per square footage. This may be counter intuitive, but being close to parks or recreational areas leads to a decrease in price per square footage. This warrants more exploration, but it may suggest that recreational areas are closer to residential areas with more two-story houses.
Naturally, houses with asbestos shingles are detrimental to price. Being adjacent to a high capacity road or railroad tracks is also detrimental towards price. Surprisingly, mansard roof style is detrimental towards price. The mansard style is very common on older houses. The largest detriment to the target variable is having an above grade kitchen.
Conclusion
A descriptive lasso regression pipeline model was implemented with a mean absolute error of -0.04 with an r-squared of 89.25% using 3-fold grid search cross validation. The primary driver of price per square footage are features related to functionality. Features associated with the condition of the house tend to increase price per square footage such as exterior and garage condition.
Features pertaining to quality, such as kitchen quality, exterior quality, and basement livability quality tend to decrease price per square footage. The inverse relationship between price and total feature square footage suggests that two story and other larger houses have a lower price per square footage. This suggests that the prevalent consumer preference in Ames is geared towards functional condition as opposed to luxurious quality, suggesting a large disparity in income distribution.
Future Studies
This dataset has so many opportunities for expansion, so the project is far from over. Here are a few upcoming additions to the project;
- Tableau Dashboard showcasing insights for neighborhood specific investment
- Gradient descent model for understanding feature interactions through partial dependence analysis
- Support vector clustering of latitude/longitude for improved neighborhood descriptive modeling
- Principal component analysis for dimensionality reduction