Ames Iowa Housing Prices Model
The skills the author demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
Objective
Our goal was to construct the most accurate possible model to predict housing prices in Ames, IA.
Background on Ames
While Ames embodies the typical college town in the Midwest, it also represents a unique combination of demographics and history. Ames has the distinction of being the only city with a population of more than 65,000 where 45% of residents are enrolled in college or graduate school. This has a distorting effect on income demographics where the median household income is $46,000 and the 28% poverty rate is nearly 3 times the national average.
The housing market prices are considerably different on the basis of median price per square foot on a neighborhood basis. The highest priced neighborhood is the Green Hill section with an average $198.65 per square foot, while the Southwest of ISU neighborhood rounds out the bottom at $89.89 per square foot.
The real estate market often utilizes price per square foot as a defining metric and “location, location, location” as a mantra. Intuitively, it would seem that basing the dependent variable on these characteristics would yield the most accurate results. In practice, the results were less accurate than using Total Living Area and Neighborhood as features and “sale price” as the dependent variable.
As the boxplot below illustrates, the median price per square foot is around $125 per foot. Using price per square foot, variance of the target variable is reduced, leading to a reduction in R Squared.

Feature Analysis and Selection - Pt. 1
In order to prepare the dataset for analysis, we cleaned the data. Duplicate records were removed. For the qualitative, categorical variables, we imputed all “NA” values with “None.” For numerical, continuous features that had missing values, we substituted the value of zero with the exception of the year the garage was built. In that case, we left the value as N/A since we did not use the feature.
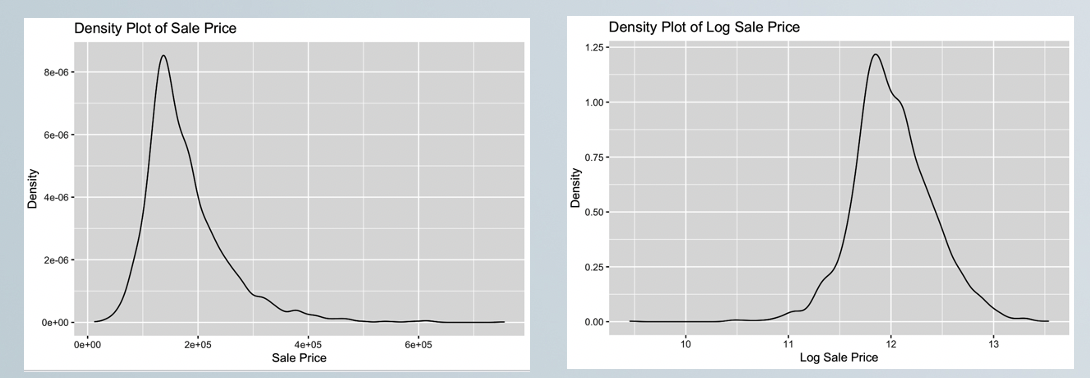
Once we investigated and cleaned the data, we began the process of determining what variables would be included in the final model. The first thing we looked into was how we wanted to view the dependent variable (sale price). We quickly realized that the best way to view was using the log of the sale price as opposed to the raw number. The reasoning for this is that the log of the sale price provided a more normal distribution of values.
Feature Analysis and Selection - Pt. 2
Next, we looked into variable creation for any variables that would be helpful to add to the data set. We wound up creating a handful of variables to help model the data.
|
Feature |
Code Name |
Calculation |
|
Total Living Area |
TotalLivingArea |
GrLivArea + TotalBsmttSF - BsmtUnSF |
|
Unused Lot Size |
UnusedLotSize |
LotArea - 1stFlrSF |
|
Has Pool |
HasPool |
PoolArea > 0 |
|
Has Basement |
HasBsmt |
BsmtQual != None |
|
Toilets |
Toilets |
HalfBath + FullBath + BsmtHalfBath + BsmtFullBath |
|
Showers |
Showers |
FullBath + BsmtFullBath |
|
House Age |
HouseAge |
max(YearBuilt) - YearBuilt + 1 |
|
House Age Squared |
HouseAgeSq |
HouseAge ^ 2 |
|
Up/Down Ratio |
UpDownRatio |
2ndFlrSF / 1stFlrSF |
Variables such as Total Living Area and Unused Lot Size were created by aggregating existing variables in the dataset because we felt the aggregated values would paint a better picture than the individual values. Has Pool and Has Basement were created because there was value in whether or not the item existed, though the actual size wasn’t particularly relevant.
Feature Analysis and Selection - Pt. 3
Once the necessary variables were added to the data set, we looked into the correlation across metrics to try and identify possible multicollinearity before beginning to model.

We also looked into how the individual metrics correlated with sale price.


Once we completed this process, we selected our variables for the initial modeling

Modeling the Prices of Houses in Ames
After selecting the overall features, they were separated into continuous, numeric and discrete, categorical variables. The categorical variables were “dummified” into a series of columns in which each column stood for a different value of the category. For instance, each neighborhood was represented by a column. All except one column would have zeros as values; the one column that represented the value of the feature would have a one as the value. This approach is known as One Hot Encoding.
The next step was to divide the features and targets into a training set (80% of the data) and a test set (the remaining 20%). The training set was used to fit the model while the test set was put aside to ensure that we did not overfit.
Once the data was prepared, the following models were tested:
- Linear Regression
- Random Forest
- XGBoost
- LightGBM
- CatBoost
- Support Vector Machine
Linear Regression
In order to decrease multicollinearity and arrive at the most pertinent variables, Lasso regression was applied to the data set after scaling the variables. A grid search was performed on a variety of alpha penalization rates until we achieved a maximized test score where alpha equalled 4.6 x 10-5.

This resulted in the following coefficients:

Since the regression model predicted the log of the sale price, we can interpret the coefficients to mean that an increase in one unit of a given variable increases the log of the sale price by that coefficient (as long as all other variables are kept constant). For example, an increase of an additional square foot of Total Living Area would increase the log price by 2/100th of a cent.
Boosting Models for Ames House Price Data
Boosting models are high-performing tree-based models. These models combine decision tree algorithms with boosting methods that train weak learners sequentially rather than in parallel like a Random Forest. Each subsequent tree in the boosting model attempts to correct the error of its predecessors.
Three variants of the boosting algorithm were tried:
- CatBoost
- LightGBM
- XGBoost
Each took a significant period of time to cross-validate the hyperparameters, so training was slow in general. What these models lacked in training speed, they more than made up for it in accuracy.
Depending on the model, different hyperparameters were tuned accordingly. Common among all of these were learning rate and maximum depth. CatBoost also offered a hyperparameter for L2 leaf regression. From our cross-validation, we learned that our best CatBoost model came from having a maximum depth of 7, an L2 Leaf Regularization parameter of 1, and a learning rate of 0.03.
Cross-Model Comparison
The following table details the best version of each model. From the table, we see that the boosting models tend to overfit, but the testing scores still outperform the other models.
|
Model |
Training R2 |
Testing R2 |
Best RMSE |
|
CatBoost |
94.65% |
91.62% |
0.113 |
|
LightGBM |
97.40% |
91.00% |
0.117 |
|
XGBoost |
99.35% |
90.89% |
0.118 |
|
Random Forest |
97.86% |
89.66% |
0.126 |
|
Support Vector Machine |
90.38% |
88.30% |
0.134 |
|
Linear Regression |
87.00% |
88.24% |
0.138 |
Conclusion
Among the estimated models, the best performing model is the CatBoost model. It explains around 92% of the variance in the dependent variable log sales price (Root mean squared error: 0.1135). As mentioned previously the model was estimated on a train data set and finally applied on a test data set. It is therefore an out of sample estimation.
Based on the variable importance plot the most important feature is the overall quality followed by the total living area. These two features capture 30 percent and 27 percent of the explained variance.
Variable Importance Plot
|
Feature |
Importance |
|
Overall Quality (OverallQual) |
31% |
|
Total Living Area (TotalLivingArea) |
27% |
|
House Age Squared (HouseAgeSq) |
9% |
|
Garage Area (GarageArea) |
7% |
|
Neighborhood (Neighborhood) |
6% |
|
Overall Condition (OverallCond) |
5% |
|
Unused Lot Size (UnusedLotSize) |
4% |
|
# of Toilets (Toilets) |
4% |
|
Basement Quality (BsmtQual) |
3% |
|
Sale Condition (SaleCondition) |
2% |
|
Building Type (BidgType) |
1% |
|
Lot Frontage (LotFrontage) |
1% |
|
Upstairs/Downstairs Ratio (UpDownRatio) |
1% |
A downside of the model is that we cannot directly interpret the effects of the explanatory variables on the log sales price. This is a common disadvantage of this type of blackbox model where a direct interpretation is not possible. We can, therefore, not make a claim about how much the price will increase when the overall quality is improved or when there is an additional bathroom. Despite this disadvantage, the model still provides a good guideline for what an investor should consider when buying a house. An investor should definitely look at the mentioned features such as the overall quality of a house or the age.
A nice advantage of our analysis is that we can make a direct prediction of a house's price as long as we have the considered explanatory variables from our model. Let’s assume we have a house with Overall Quality of 6, a total living area 330 square feet, a house age of 10 years; our model predicts a sale price of $420,000 USD. This can be compared to the offered price of a house with the same features for example on a web page such as Zillow. The comparison of our estimation and the offered price gives an investor a clear guideline if he should invest. An investor should invest if the offered price is lower in comparison to our estimated price.