Navigating the Common Data of Real Estate in Ames Iowa
The skills the author demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
Anthony Ali, Elina Egiazarova, Swarup Malli, and David Zask
Github
The objective of the project is to leverage data and advanced regressions techniques to predict home prices in Ames, Iowa. The source dataset consisted of train and test csv files. The train csv file was used for training the ML algorithm.
The train data set consisted of 1460 rows and 79 variables. The data set consists of data from 2006 to 2010. There are 38 numeric features and 41 categorical variables. First, we had to Normalize the numeric data as it was right-skewed. We then dealt with the categorical variables by splitting them into nominal and ordinal features.

Data analysis
In order to build linear models to predict prices, we first need to analyze and prepare the data.
Zero Values
First, we notice that there are features that have over 95% zero values. This means that, for the majority of the properties in our dataset, the values for these features are the same. Therefore, they don't contribute to the changes in prices and we may omit them when choosing the features that influence those changes. So we remove PoolArea, LowQualFinSF, 3SsnPorh.
We also observe that the issue is not unique to features with zero values: there are categorical features where almost all values are the same. Again, we treat them as information that can not help us predict prices given that their values are almost always the same for each property. Therefore, we remove the features Street, Condition2, Utilities (100% values are the same for the latter - all houses have all public utilities).
A few features in our dataset have very few unique values and are categorical. For those, we see if we could reduce the number to two (as is the case for LandSlope when a third value appears only 4 times) and then transform them to binary values - 0 and 1.
Removing Outliers
To preserve the linearity of the relationship between numerical features and the prices, we need to check for the outliers and remove them, when possible. Some features (LotFrontage, LotArea) have clear outliers that could be removed. This helps to restore the linearity significantly.
For both numerical and categorical features, we check for missing values and impute them with zeros (for numerical features) when appropriate (the feature of the house is not present, e.g. pool, basement). LotFrontage is imputed with mean values for each Neighborhood, and MiscFeature is removed as it turns out to have 96% of its values missing.
Finally, we log transform highly skewed numerical features and dummify the categorical features. Our dataset is now ready for modeling.

Some features showed a clear linear relationship to price.
Modeling:
Linear Regression
After completing the data analysis, we needed a baseline to see how our models would perform, so we tested out training data using a basic Linear Regression model. The results from this test gave us an R² of 0.9128 and an RMSE of 0.1198.
Lasso Regression
We then reduced features using Lasso Regression to make our models more accurate. In order to test this, we ran the different models with test data from before the feature reduction and after. Our first model was the Lasso Regression model, which resulted in an RMSE of 0.1180 before the feature reduction and an RMSE of .01103 after. This difference in results showed that the feature reduction made our model more accurate.
Ridge Regression
We then proceeded on using our training data with a Ridge Regression model, which resulted in an RMSE of 0.1225 before the feature reduction and 0.1142 after the feature reduction. Once again the model performed better after the reduction, though not as well as the Lasso Reduction model. The final linear based model that was utilized was our Elastic-Net with Cross-Validation model. This model resulted in an RMSE of 0.1215 before the reduction and an RMSE of 0.1094 after the reduction, making it the best performing model of the linear based models we tested.
In order to determine whether we could get more out of our model and if we could drop more irrelevant features, we turned to Gradient Boosting to further optimize our model. In tuning our model we saw that there was going to be inherent overfitting on the training data because of how powerful the learning algorithm was. We performed a grid search in order to minimize this problem.
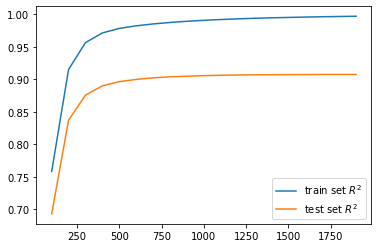
Overfitting on the training data measured by R-squared value.
With fully optimized parameters the model had an R-squared value of 0.92 and an RMSE of 0.11 meaning that it performed very well, but only marginally better than the other models. The real value of Gradient Boosting was that we were able to identify the important features and eliminate the unimportant ones without a significant impact on model performance.
We saw that only a few features had much impact on the model and that feature importance quickly dropped off after those features. When we tested the model only using the 15-most important features (there were 63 used in the original model) we saw a very modest drop in performance. The R-squared value was 0.87 and the RMSE was 0.12. Thus, we concluded that the most informative model was a limited feature Gradient Boosted model.

Conclusion:
So what really matters when it comes to housing prices? The most important feature by far was Overall Quality followed by Living Area and then Neighborhood followed by another steep drop in feature importance. We recommend that home buyers/sellers focus on quality first and foremost. Quality is the first thing to depreciate over time and must be tended to when preserving the value of a home.
This means that any work on the home should be focused on maintaining functionality as opposed to expensive additions or remodels. Living area SF and neighborhood are also important determinants of price, so be aware of size and location when purchasing a home. If a home is lacking in these qualities and still has a hefty price tag then it is probably not worth the extra money.