Data Study on NYC Public Schools' SAT Scores
The skills the author demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
Goal
This project aims to visualize SAT score data for New York City public schools and identify any underlying trends. This project will focus on two main questions:
- Which NYC public schools score the highest/lowest on the SAT?
- Why? Or, what characteristics differentiate top and bottom schools?
To address the second question, we will look at the characteristics that differentiate top and bottom schools. This analysis will also attempt to find characteristics that a school can improve in order to increase its likelihood of a higher average SAT score.
Introduction
This project will explore data that New York City publishes on its public school system. The city provides a large amount of public data, which can be easily accessed through the NYC Open Data website. The goal of the website is to provide access to public city data to all so that anyone can analyze and improve government services through a better understanding of the data. This project will focus on two datasets provided by the New York City Department of Education (NYCDOE) on the city's public school system:
The first dataset includes the most recently published SAT scores for each school and extensive data on the learning environment, while the second dataset includes location data of each school. Although there are additional datasets that we could include in the analysis, for consistency we will only focus on data from the 2014-2015 school year.
SAT Data Overview
First, we'll perform some basic exploratory data analysis on the SAT data. As background, the SAT has three sections (Math, Reading, and Writing) worth 800 points each, for a maximum total score of 2400. In our dataset, the mean public school score is 1273 and the median is 1227, meaning the distribution is skewed slightly to the right with more high-scoring outliers.
 In total, there are 491 public schools in the dataset. Schools with fewer than 10 test takers do not have scores available in the dataset and as a result, 82 (or 16.7%) of the schools are missing an average SAT score. This may be a case of missingness not at random (MNAR), as schools with fewer test takers could arguably be the schools that score the lowest, which would affect the analysis. However, as this is the outcome variable, we are unable to impute this value and therefore this analysis will only focus on schools that have scores available.
In total, there are 491 public schools in the dataset. Schools with fewer than 10 test takers do not have scores available in the dataset and as a result, 82 (or 16.7%) of the schools are missing an average SAT score. This may be a case of missingness not at random (MNAR), as schools with fewer test takers could arguably be the schools that score the lowest, which would affect the analysis. However, as this is the outcome variable, we are unable to impute this value and therefore this analysis will only focus on schools that have scores available.
Sections of SAT
Each SAT score is comprised of results from three section: Math, Reading, and Writing. Each subsection has a similar score distribution, as seen in the violin plots below.

The boxplots within each violin plot show that the Math section has the highest average score of all the sections (432), followed by Reading (423), and Writing (418). Math also has several high outliers, indicating that a few schools have a relative strength in Math.
Correlations
Lastly, if we run a correlation, we can see that the scores for each section are highly correlated with each other, meaning a school that has a high or low average score on one section will very likely have a similar score on the other two sections. As we might expect, the Reading and Writing sections are more closely correlated with each other (+0.99 correlation) than with the Math section (+0.93 and +0.94, respectively). This is unsurprising as the Reading and Writing sections test very similar skills, so a school that does well on one of these sections could be strongly expected to do well on the other.

Data on Top Schools
Let’s take a closer look at the schools that have SAT scores in the 90th percentile (top 10%) for New York City. The top three public schools with the highest total SAT score are well-known: Stuyvesant High School, Staten Island Technical High School, and Bronx High School of Science.

Top Schools by SAT Sections
We can also view the top schools by section. Almost all of the schools in the top 10% scored higher on the math section than either of the other sections. As we can see in the section breakdown, some schools are stronger in Math, but weaker in Reading and Writing, and visa versa. Unsurprisingly, schools that have the words "technical" or "science" in their name do better on the math section, while schools with the words "art", "music", or "bard" tend to be stronger in Reading and Writing.

Bottom SAT Scores in Top Schools
Similarly, we can look at schools that are in the 10th percentile, or bottom 10%. Keep in mind that schools with less than 10 students taking the SAT do not have their scores available in the dataset, which could potentially affect our analysis. These missing observations comprise 82 (or 16.7%) of the NYC public schools in the dataset.

We can also view the bottom schools by section. Again, we can see that some schools are stronger in Math, but weaker in Reading and Writing, and visa versa. However, here the two schools with the word "technical" in their names actually did worse on the Math section than on the Reading/Writing sections. This reflects an interesting trend, namely, that schools in the top 10% tend to do better on the Math section than the other two sections, while schools in the bottom 10% tend to do worse on the Math section than the other two.

Findings
In general, some schools have a much stronger math score than reading and writing scores.

The school with the highest spread between sections is Flushing International High School, which has an average math score of 481, but reading and writing scores of 323. This spread of over 150 points is likely due to the fact that 81.7% of students at this school are English Language Learners (ELL), or non-native English speakers, which is a significant disadvantage for reading/writing. What other characteristics can we look at to explain school performances?
School Characteristics
Let’s take a look at some of the different characteristics of each school recorded in the data. The characteristics we will look at are:

We can run a correlation of these characteristics with a school's average SAT score to identify which characteristics are most and least associated with a high average SAT score.

The strongest positive correlation to a high average score is a high student attendance rate (+0.63), while the strongest negative correlation to a high average score is a high Economic Need Index (-0.76). The Economic Need Index reflects the socioeconomic status of the school population and is a metric calculated by the NYCBOE as: (Percent Temporary Housing) + (Percent HRA-eligible * 0.5) + (Percent Free Lunch Eligible * 0.5).
However, it is important to keep in mind that correlation does not imply causation. Therefore, using correlation, we can identify associative properties between school characteristics and SAT scores, but we can't assume that there is a causative or predictive relationship between any characteristic and SAT score by only using correlation.
The breakdown of characteristics to each the average score on each section is fairly similar:

Below, student attendance rate is plotted against average total score:

And the most negative factor:

We can also see the correlation of these characteristics with each other using a correlation matrix ordered using hierarchical clustering (grouping each characteristic with the most similar characteristics) and then removing the correlation of each characteristic with itself. As we can see, there is high multicollinearity, meaning many of the variables are highly correlated with each other. In order to create an accurate model, we generally want to remove any multicollinearity.

PCA Data Analysis
Because of the large number of variables and high multicollinearity, we can perform a principal component analysis (PCA) to reduce the number of dimensions in the data and identify the dimensions that account for the most variation between observations.
We can see that some of the variables are essentially repetitive and measure the same underlying metric.
However, using the principal components instead of the variables results in less interpretive results so we will not run the analysis on these principal components.
Importance of Characteristics
After looking at the correlation between different school characteristics and average SAT scores, we noticed that certain characteristics were associated with a higher average SAT score. Can we show a predictive relationship between the two?
First, we'll run a multiple linear regression using all the variables. The resulting model has an adjusted R² value (coefficient of determination) of 0.9431 and the regression is statistically significant (p-value < 2.2e-16). We can see the relative importance of each variable in this model below. This graph uses Shapley Value Regression, an averaging of the sequential sum-of-squares obtained from all possible orderings of the independent variables to show the percent contribution of each variable to the model.

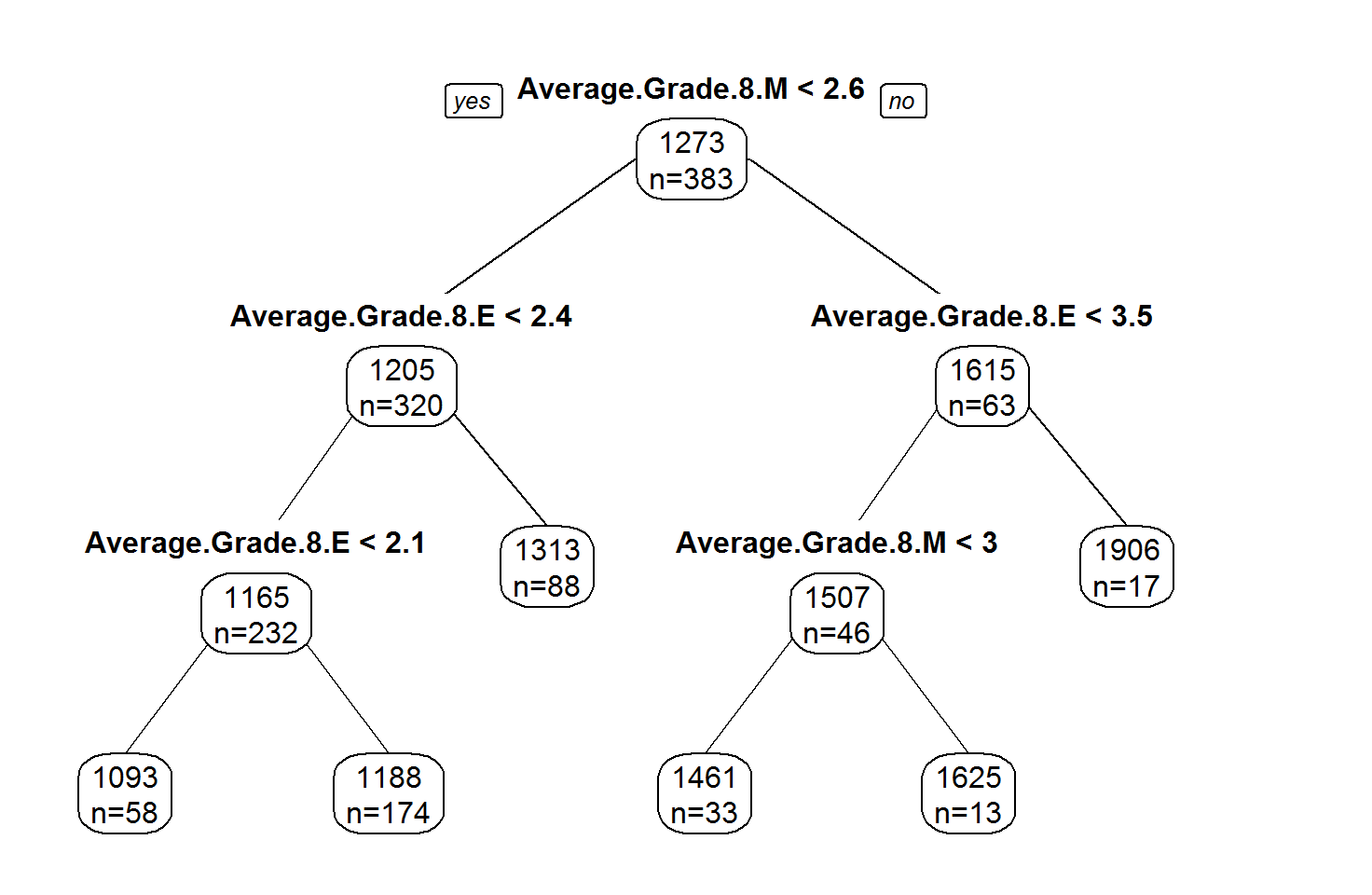
We can also run a random forest model on the data to assess the variable importance. One of the advantages of the random forest model is that it is largely robust against multicollinearity. The random forest model is a more advanced version of a decision tree, which is shown below. To predict a school's average SAT score, the decision tree only uses the standardized test scores because of their very high predictive value.
{kind=link}

The standardized tests have the highest variable importance in the random forest model as well, although the other variables are ordered differently than in the multiple linear regression model.

School Location
Lastly, does location play a role in a school's average score? There are too few schools in each zip code to draw meaningful statistical conclusions, but we can break it down by borough. Schools in Staten Island have the highest average score, while schools in the Bronx and Brooklyn have the lowest average scores.
At the same time, Staten Island also has the fewest public schools by far of all the boroughs (10 schools), while Brooklyn and the Bronx have the most (over 120). The fact that having more schools in a borough tends to be associated with a lower score could be due to resources being allocated better when there are fewer public schools in a borough and therefore better schools, although this definitely needs additional research.

Conclusions, Future Steps
Understanding the factors that result in higher SAT scores can help schools better identify which areas to improve in order to score higher on the test. Using a linear regression model and random forest model as examples, we can see which characteristics are better predictors of a school's average SAT score. Overwhelmingly, students' standardized test scores from eighth grade play the largest role in predicting SAT scores. However, one factor that seems feasible for schools to change is the student attendance and chronic absences, which were significant in both models.
Presumably, this analysis would look similar for other years as well as for other major cities, and it would be interesting to see if there are any significant differences. Another interesting application of this analysis would be adding charter schools or private schools in order to compare the efficiency of different types of schools, although this data is not readily available. Lastly, this type of analysis could be extended to examining Regent exam scores in light of recent controversy with certain NYC schools being suspected of cheating on the Regent exams.
Please feel free to build on this analysis or to reach out to me with any comments, criticism, or other feedback.