LendingClub Loan Default Forecasts Using Machine Learning
The skills the authors demonstrated here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
Introduction to LendingClub - Pt. 1
LendingClub was a peer-to-peer lending platform that connected investors to borrowers. They were an alternative to the traditional bank lending system. One of the appeals of LendingClub is that the loans they facilitated were of lower interest rates compared to banks because LendingClub only took a flat fee from the transaction whereas traditional banks take part in the interest payments. Also, investors liked this because they would be able to keep more of the profits from the loan payments compared to what they would get from traditional bank loans.
Introduction to LendingClub - Pt. 2
Loans are sums of money that are lent to the borrower with the expectation that they will pay back the principal plus interest over the allotted time. There is always a risk involved with loans from the perspective of the investor. The way to mitigate the risks and make it worth your while is to increase the interest rate and the risk increases.
The risk comes from the applicant's financial history. If the applicant has a strong financial history, then you would suspect that they are low-risk for default, so you give them a low-interest rate on their loan. If an applicant has a weak financial history, then you would suspect that they are high-risk for defaulting, then you would increase the interest rate on their loan to make it worth your while.
The higher the interest rate, the higher the potential profits are for the investor, provided the borrower does not default on the loan or get charged off. This is why it is so important for the investor to be able to have some tools to help them decide whether or not they want to accept a loan application or reject it.
What does it mean to default on a loan? Loan default means that the borrower failed to adhere to the initial agreement they made for the loan. This is detrimental to an investor.
Data Analysis - Pt. 1
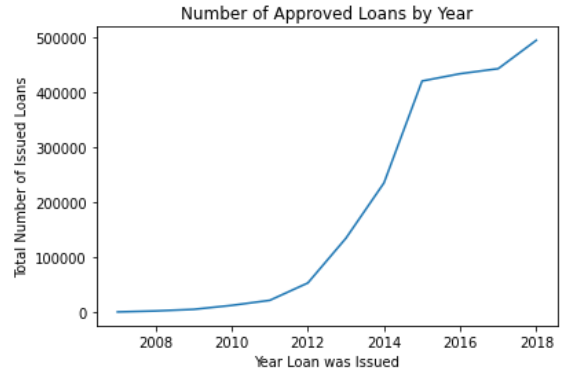
As you can see in the image above, there is a spike of activity for LendingClub around the year 2013. In 2013, the USA experienced what's now called the Great Recession.
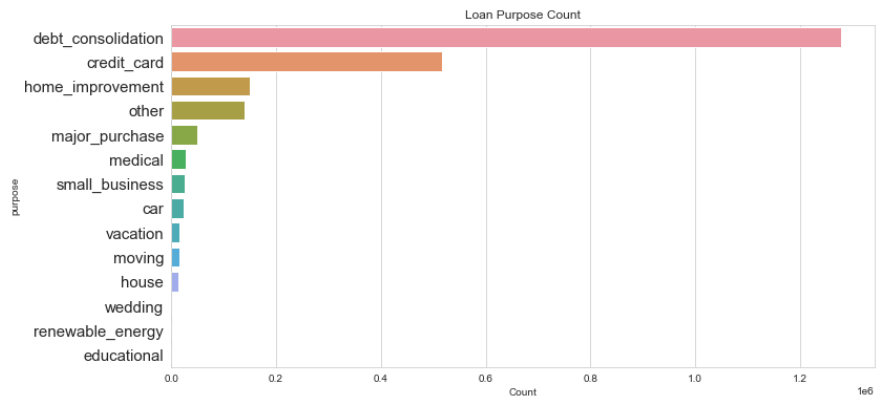
In the above graph, we see that debt consolidation was the number one purpose for loans through LendingClub. This coincides with the Great Recession of 2013.
When you think about loans that are charged off / default, you might think that loans with higher amounts tend to default more often than loans with low amounts. This seems logical, but it turns out to be false.
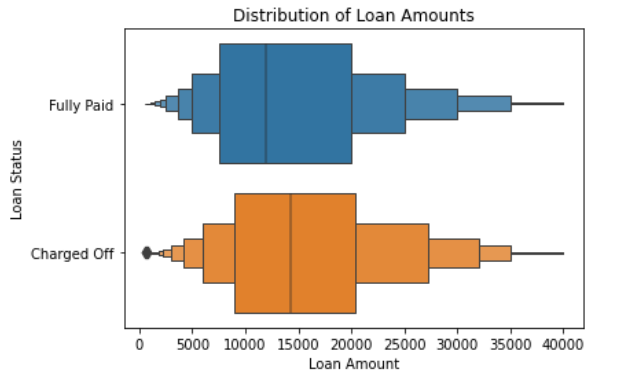
This graph shows the distribution of loan amounts for loans that were fully paid vs charged off. You can see that there is a lot of overlap between the two loan statuses. This means that one can't reliably predict whether or not a loan will default simply based on the loan amount. Also, according to the data our team had, the median salary for individuals was similar across different loan grades were very similar, so salary is not a reliable indicator for whether or not a loan would default either.
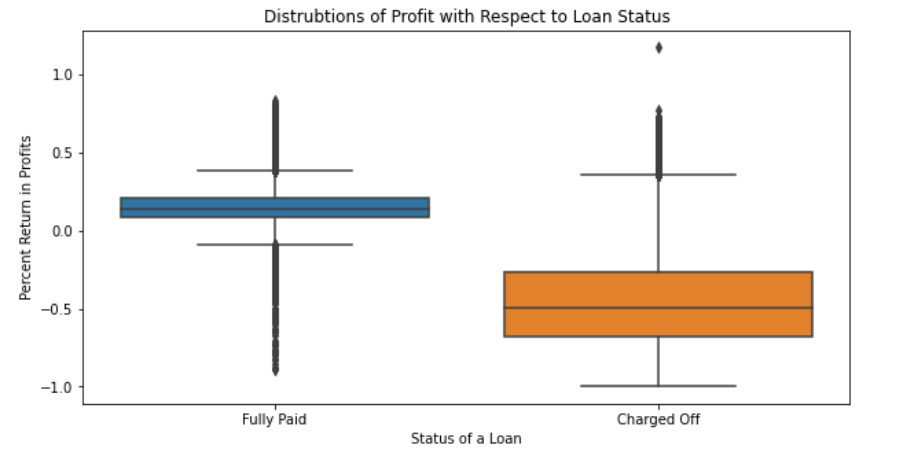
This boxplot illustrates the fact that fully paid loans increase the profits of the investors and charged off / defaulted loans are detrimental to a business. It decreases profits and the investors lose out on the principal and interest they planned on getting from the installments.
Data Analysis - Pt. 2

This graph shows the distribution of loan count by loan grade. Most LendingClub loans qualify as grade B or C.
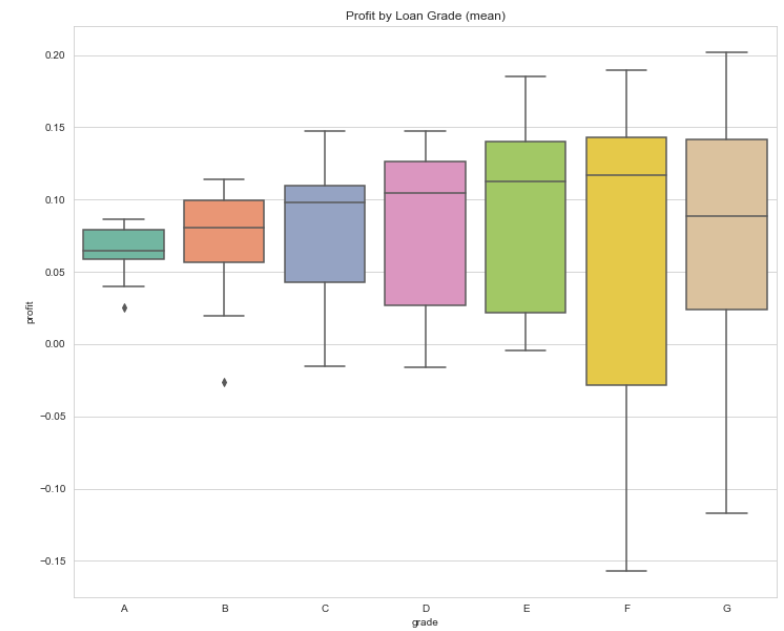
But, from the boxplot, we can see that the profit margins increase as the loan grade decreases. This means the higher loan grades are safer, but less profitable and the lower loan grades are riskier but also more profitable because of the increased interest rates. This leads to the idea of loan diversification. In order to optimize a portfolio, one needs to optimize the ratio of safe loans to risky loans. But this begs the question, how can one know which loan applications to take a risk on? Is there some way of knowing whether a loan will default or not when all you have is the financial history of the applicant?
Fortunately, there is a way to reliably predict loan defaults, thanks to machine learning. The question now is, which machine learning model to use?
Data Analysis - Pt. 3
Our team tried Logistic Regression, Random Forest, Gradient Boosting, Extreme Gradient Boosting, and Support Vector Machines. We had no real success with these models because of either overfitting or just poor model performance. But the real success came with Deep Learning.
We built a neural network that was able to find a separation between the fully paid loans class and the defaulted loans class. It did not suffer from overfitting, like the tree-based models we tried, and the computation time for a dataset of 2.5 million observations only took 15 minutes as compared to Support Vector Machines which took 5 hours on a smaller subset of the data and didn't even converge in the end. Here are the training and validation confusion matrices for the neural network.

How is this useful from a business perspective? Investors can use the model as an assistant to help them optimize their portfolio. The model can take in the financial history of the applicant and return the probability of default based on all the applicants that defaulted in the past. This will help investors minimize the number of defaulted loans in their portfolio and help them to maximize profits. They can more confidently take risks with lower loan grades and increase their profits from higher interest rates.
Future Work
In the future, we would like to build a regression model that can accurately predict the expected return on investment for a newly accepted loan, only using information from the [potential] borrower's financial history. We would also like to try to solve the overfitting problem we had with the tree-based-models. Furthermore, we would like to ensemble the tree-based models together, after solving the overfitting problem, and see if this ensembled model can out-perform the neural-network.