Olympics Medals Prediction
Introduction
Whether we like it or not, winning medals, especially gold medals, at the Olympic Games holds immense importance for every country, including the United States. A medal is a source of national pride that reflects strength and commands respect from others.
I developed a user-friendly shiny app that allows users to create their own linear regression model to analyze the factors influencing a country's medal count in the 2020 Summer Olympics (held in 2021 due to the pandemic).
The app consists of two sections:
- Data: Four graphs display information on the modern Olympic Summer Games.
- Regression: Users can create their own linear regression model to understand which variables influence a country's medal count in the 2020 Summer Olympics.
43 different libraries were used to create the App.
Please see my Github repo for details on the code details and check out the app in the following link: https://isaacchammah.shinyapps.io/olympics/
Dataset
Two distinct datasets were used, both obtained Kaggle (https://www.kaggle.com):
I. Data on 120 Years of Olympic History: details on the modern Olympic Games, from Athens 1896 to Tokyo 2020. Each row corresponds to an individual athlete competing in an individual event, including the athlete's name, sex, age, height, weight, country, medal won, and the event's name, sport, games, year, and city.
II. Global Country Information Dataset 2023: Dataset that provides a wealth of information about all countries worldwide, covering a wide range of indicators and attributes. It encompasses demographic statistics, economic indicators, environmental factors, healthcare metrics, education statistics, and much more. With every country represented, this dataset offers a complete global perspective on various aspects of nations, enabling in-depth analyses and cross-country comparisons.
Data
The following 4 hystorical charts show a brief summary of the data regarding the modern Summer Olympics:
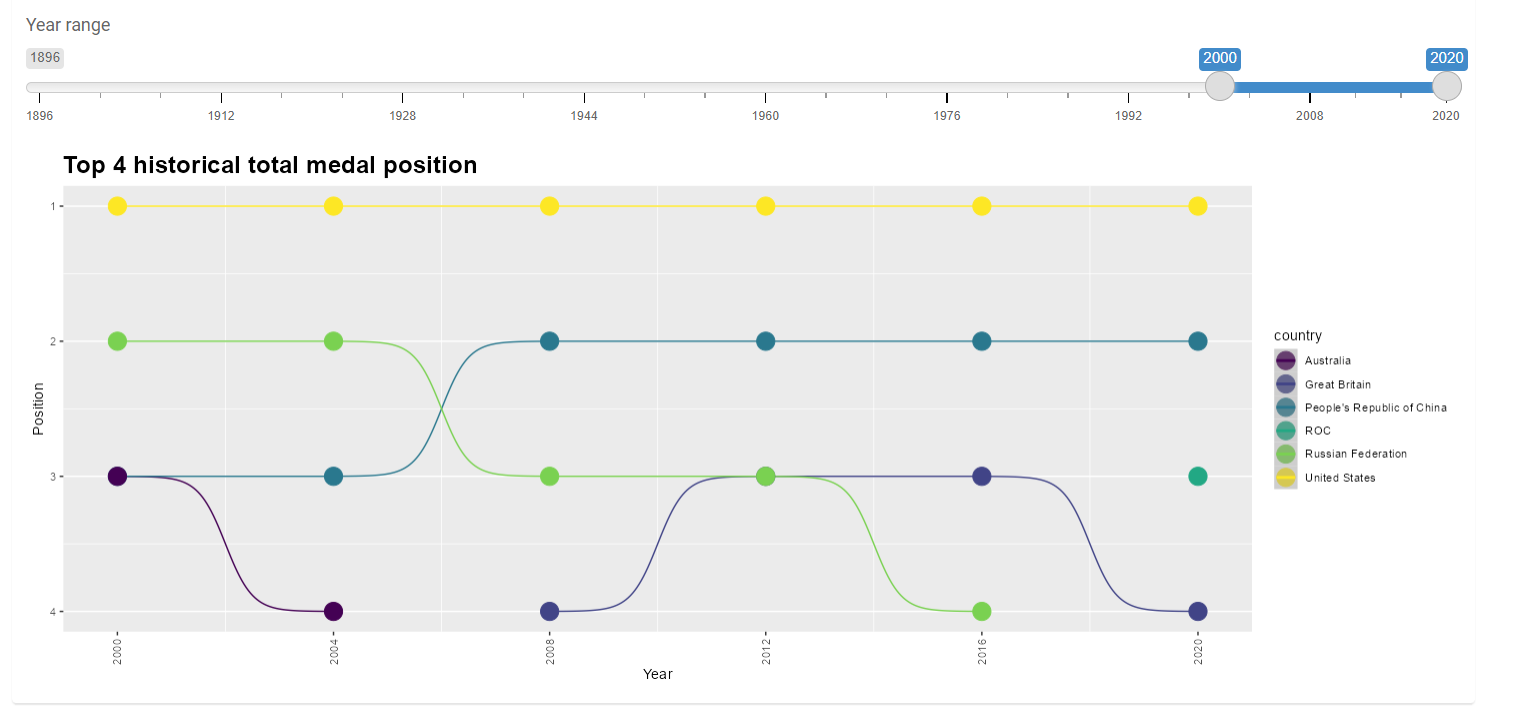
The graph displays the top 4 countries with the most medals in the selected range of Summer Olympics, including ROC (Russian athletes). These countries typically have large land areas, high GDPs, invest in sports, and send a significant number of athletes to compete.
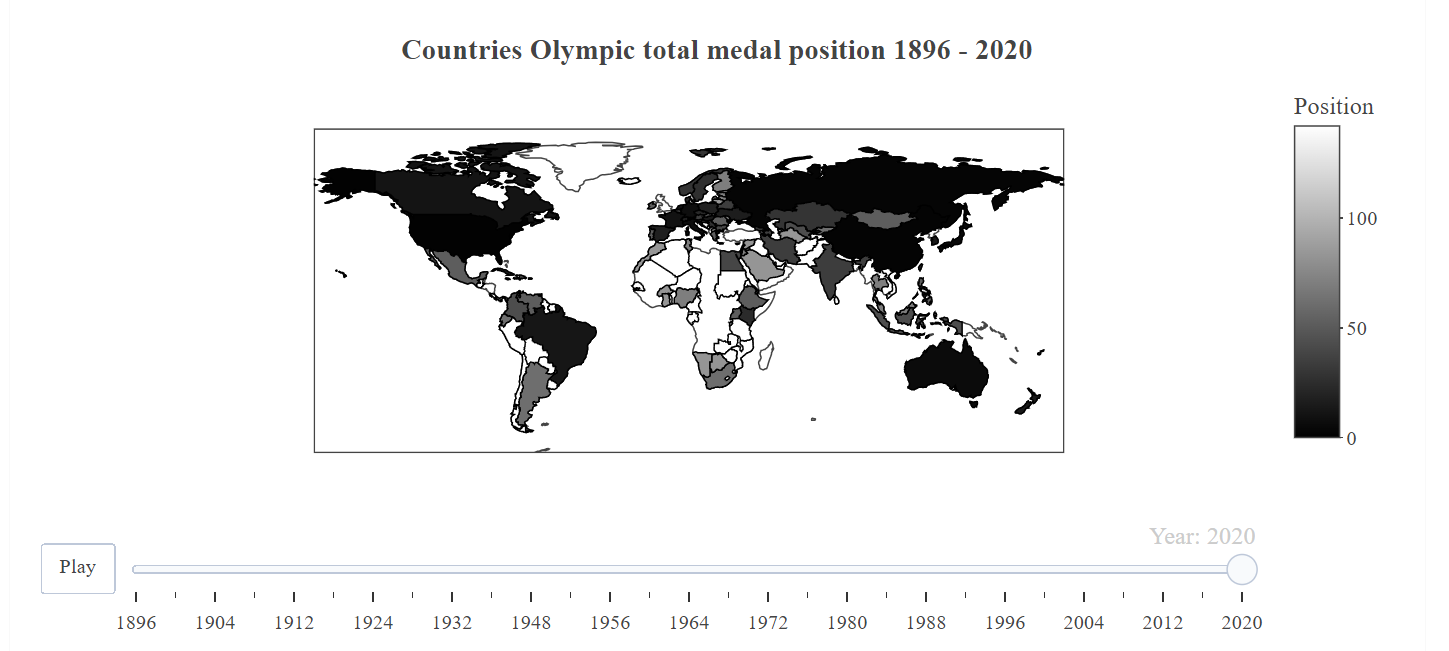
In the map, the darker shading indicates a better position for each country based on the medals won each year since 1896. In the selected year of 2020, it is evident that larger countries with more athletes and higher GDPs tend to win a greater number of total medals.
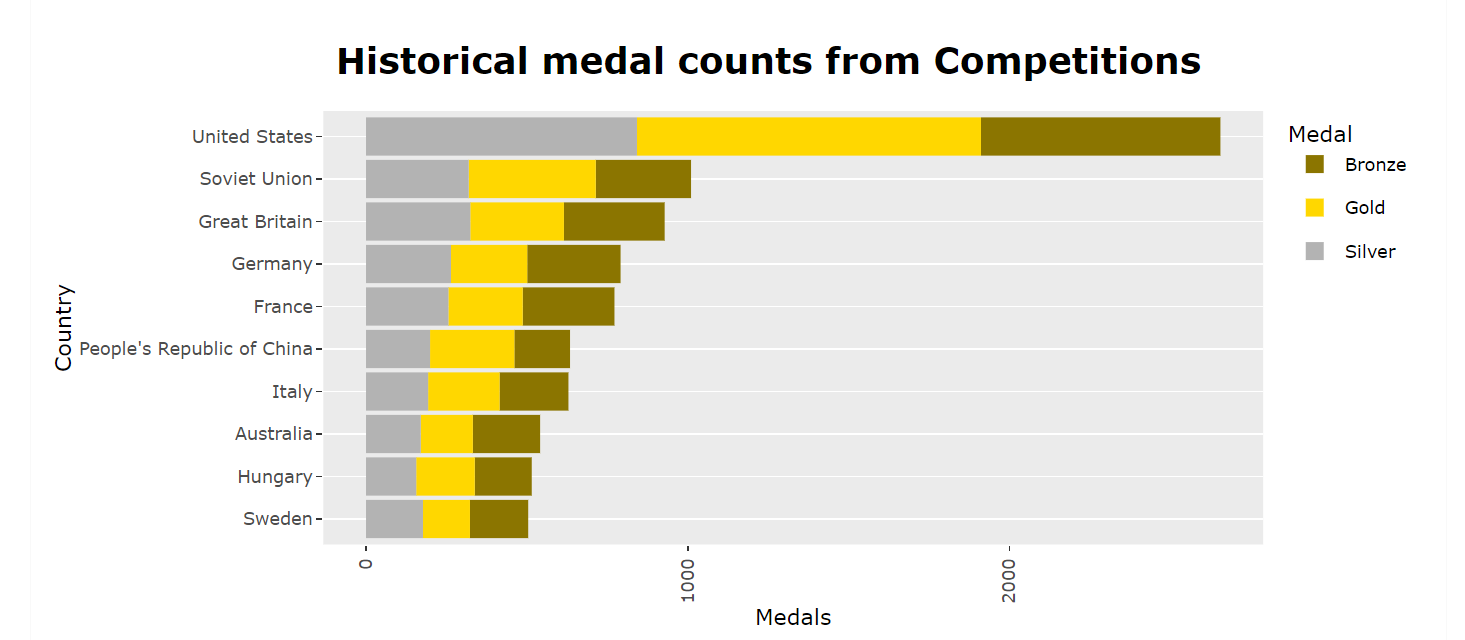
The bar chart demonstrates the United States' dominant position in winning medals. Notice that all of these countries are currently considered developed countries. ( World Bank and the U.N. Development Program classify China as an "upper middle income" country, and for the sake of these article China was classified as a developed country.)
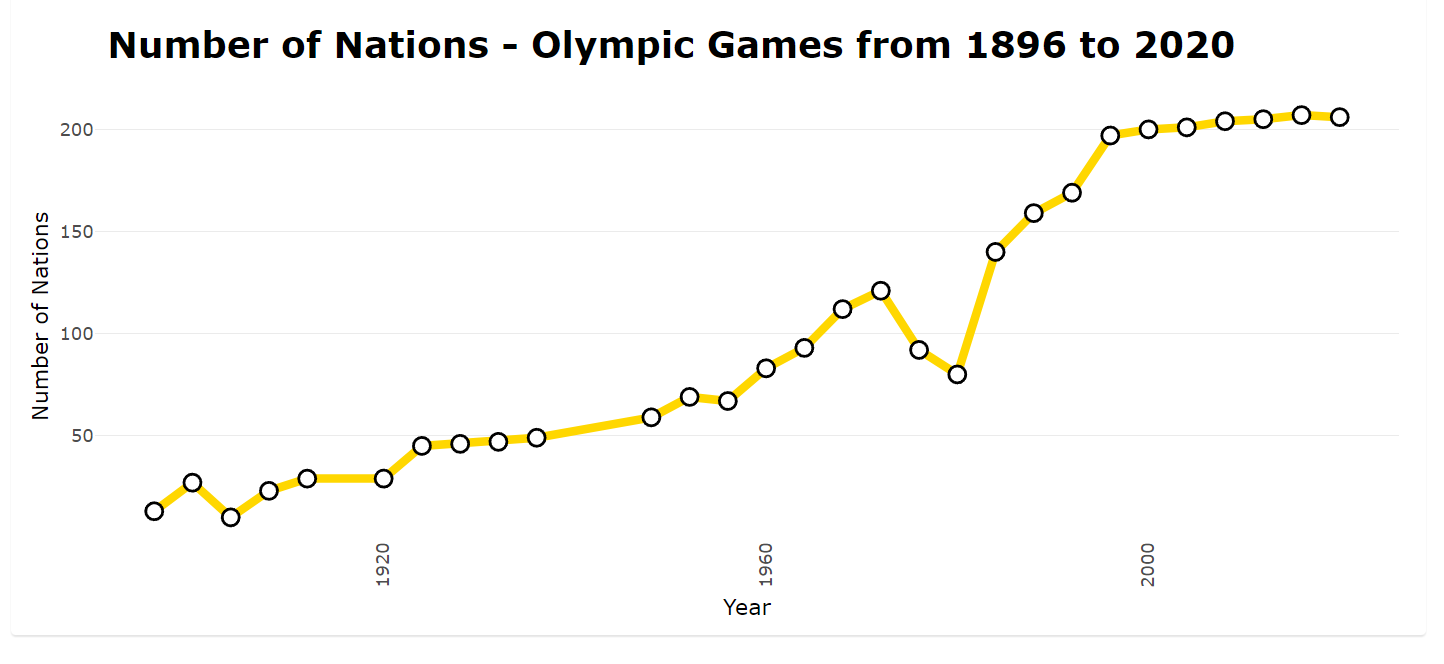
In this line graph, we observe a steady increase in the number of nations participating in the games over the years. However, there was an exception in the 1980 games when the United States led a boycott of the Summer Olympic Games in Moscow to protest the late 1979 Soviet invasion of Afghanistan. In total, 65 nations refused to participate, while 80 countries sent athletes to compete. Additionally, the games were canceled in 1916 due to World War I, and in 1940 and 1944 due to World War II.
Regression
Multiple Linear Regression (MLR) is a statistical technique that uses multiple explanatory variables to predict the outcome of a response variable.
The goal of MLR is to model the linear relationship between the independent variables and dependent variables. It extends ordinary least-squares (OLS) regression by involving more than one explanatory variable.
This application allows users to go through the step-by-step process of MLR in a didactic and intuitive manner. Some background in statistics is recommended for optimal use. It is suitable for classroom exercises for students learning to build an OLS model.
The application enables users to build an MLR model to predict variables that may influence the medal count of a country in the Olympic Games.The provided dataset is from the 2020 Summer Olympic Games, collected from 192 out of 206 participating teams.
How it works
The app has the following tabs:
Variables: Displays available description of independent and dependent variables in the dataset.
Data: Shows all available data and can be filtered for developed or developing countries.
Data Summary: Provides a summary of the variables.
Multicollinearity: Shows the correlation matrix between selected independent variables. High correlations may affect model accuracy.
Plots: The first graph displays the correlation matrix between independent variables and the dependent variable. The second graph shows the linearity of this relationship.
Model: Builds an MLR model based on selected region and checks for homoscedastic errors, normally distributed errors, and non-autocorrelated errors.
Model: Developed x Underdeveloped Countries: Compares regression models for developed and developing countries.
Model Selection: Creates a model using the Akaike Information Criterion (AIC) to estimate prediction error and select the best model with optimal predictive power and minimal predictor variables.
Conclusion: Provides a brief discussion of the results found.
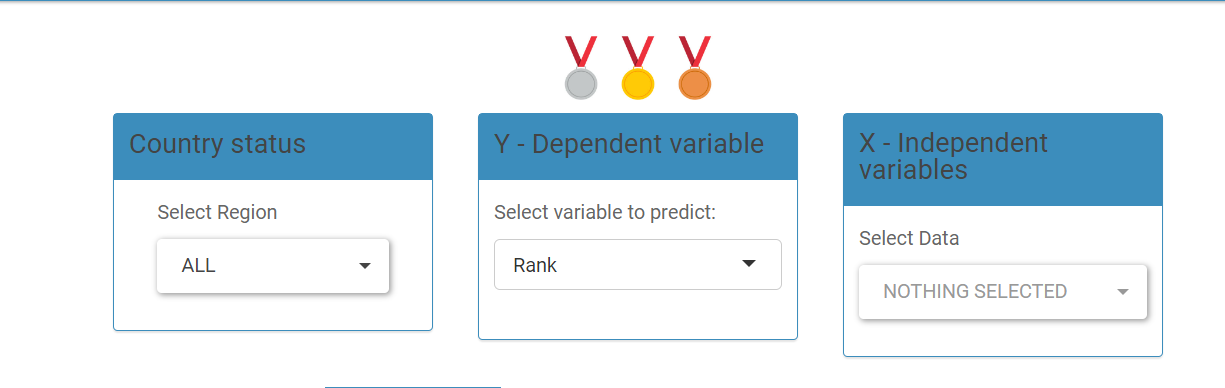
As seen in the image above, the user begins by selecting the country status to filter the countries they want to include in the multiple linear regression (MLR) analysis. They then choose the dependent variable they wish to analyze, as well as the independent variables they believe may influence the dependent variable.
Bellow is a brief description of the variables collected:
Country Status
- Developed: GDP/capita in the country is higher then $12,000
- Underdeveloped: GDP/capita in the country is lower than $12,000
Dependent variables
- Gold: Gold medals
- Silver: Silver medals
- Bronze: Bronze medals
- Total: Total medals
- Rank: % of medals won out of all medals
Independent variables
All independent variables can also be chosen in their log form
- Density (P/Km2): Population density measured in persons per square kilometer.
- Agricultural Land (%): Percentage of land area used for agricultural purposes.
- Land Area (Km2): Total land area of the country in square kilometers divided by one million.
- Armed Forces Size: Size of the armed forces in the country.
- Birth Rate: Number of births per 1,000 population per year.
- CO2 Emissions: Carbon dioxide emissions in tons.
- CPI: Consumer Price Index, a measure of inflation and purchasing power.
- CPI Change (%): Percentage change in the Consumer Price Index compared to the previous year.
- Currency_Code: Currency code used in the country.
- Fertility Rate: Average number of children born to a woman during her lifetime.
- Forested Area (%): Percentage of land area covered by forests.
- Gasoline_Price: Price of gasoline per liter in local currency.
- GDP: Gross Domestic Product, the total value of goods and services produced in the country in USD.
- Gross Primary Education Enrollment (%): Gross enrollment ratio for primary education.
- Gross Tertiary Education Enrollment (%): Gross enrollment ratio for tertiary education.
- Infant Mortality: Number of deaths per 1,000 live births before reaching one year of age.
- Largest City: Name of the country's largest city.
- Life Expectancy: Average number of years a newborn is expected to live.
- Maternal Mortality Ratio: Number of maternal deaths per 100,000 live births.
- Minimum Wage: Minimum wage level in local currency.
- Out of Pocket Health Expenditure (%): Percentage of total health expenditure paid out-of-pocket by individuals.
- Physicians per Thousand: Number of physicians per thousand people.
- Population: Total population of the country divided by one million .
- Population: Labor Force Participation (%): Percentage of the population that is part of the labor force.
- Tax Revenue (%): Tax revenue as a percentage of GDP.
- Total Tax Rate: Overall tax burden as a percentage of commercial profits.
- Unemployment Rate: Percentage of the labor force that is unemployed.
- Urban Population: Percentage of the population living in urban areas.
- Individual Athletes: Number of athletes competing individually for a country
- Team Athletes: Number of teams competing for a country
- Percentage male individual (%): Percentage of individual athletes who are male
- Percentage male team (%): Percentage of teams that are composed of male athletes
- GDP/capita: GDP divided by population size
- Country Status: If the GDP/capita was lower than $12,000 the country was considered Underdeveloped, else Developed
Best model
In this article I will show what is the model that was considered the optimum model.
Despite the large number of independent variables, only 4 variables were enough to have a model that meets all the assumptions of a multiple linear regression (multicollinearity, linearity, constant variance, normality, independent errors) and that presents a high R2 .
All of the countries were selected, the total number of medals was chosen as the dependent variable and the following 4 variables were chosen as independent: Land Area (Km2) , Gdp, Individual Athletes, Log Co2 Emissions
As seen in the two charts below, the dependent and independent variables have a positive linear correlation between each other.
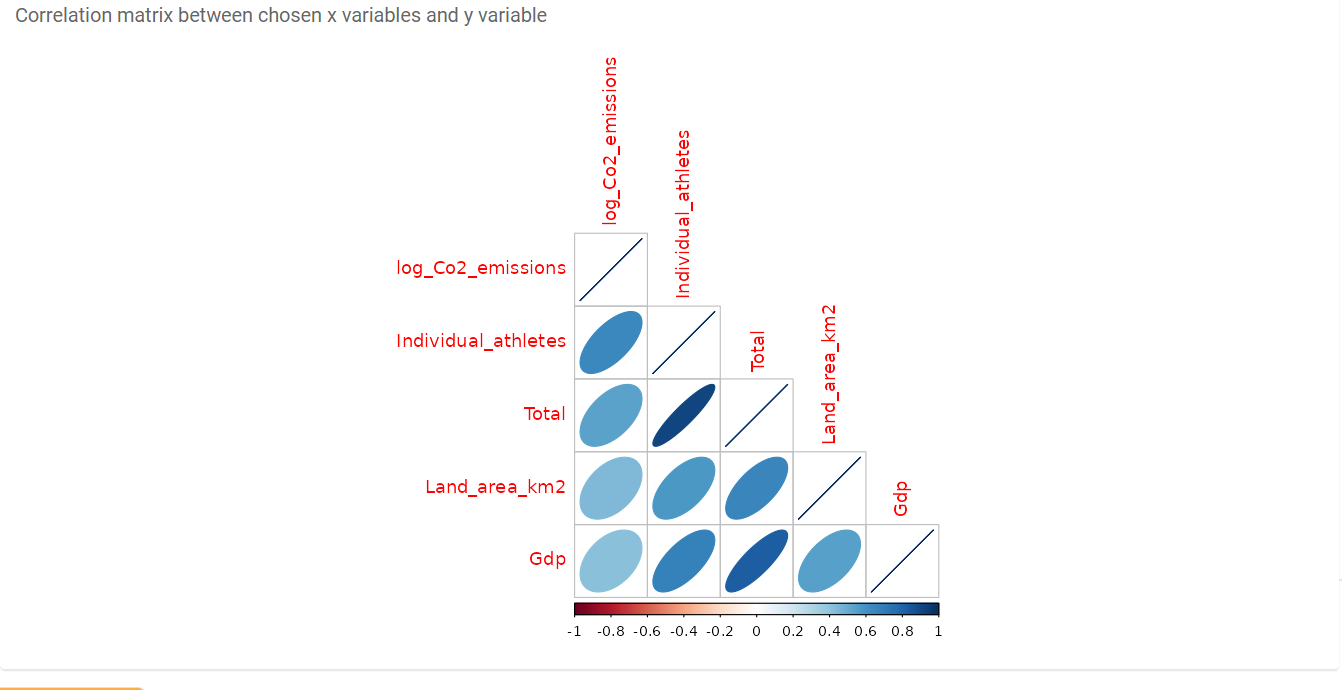
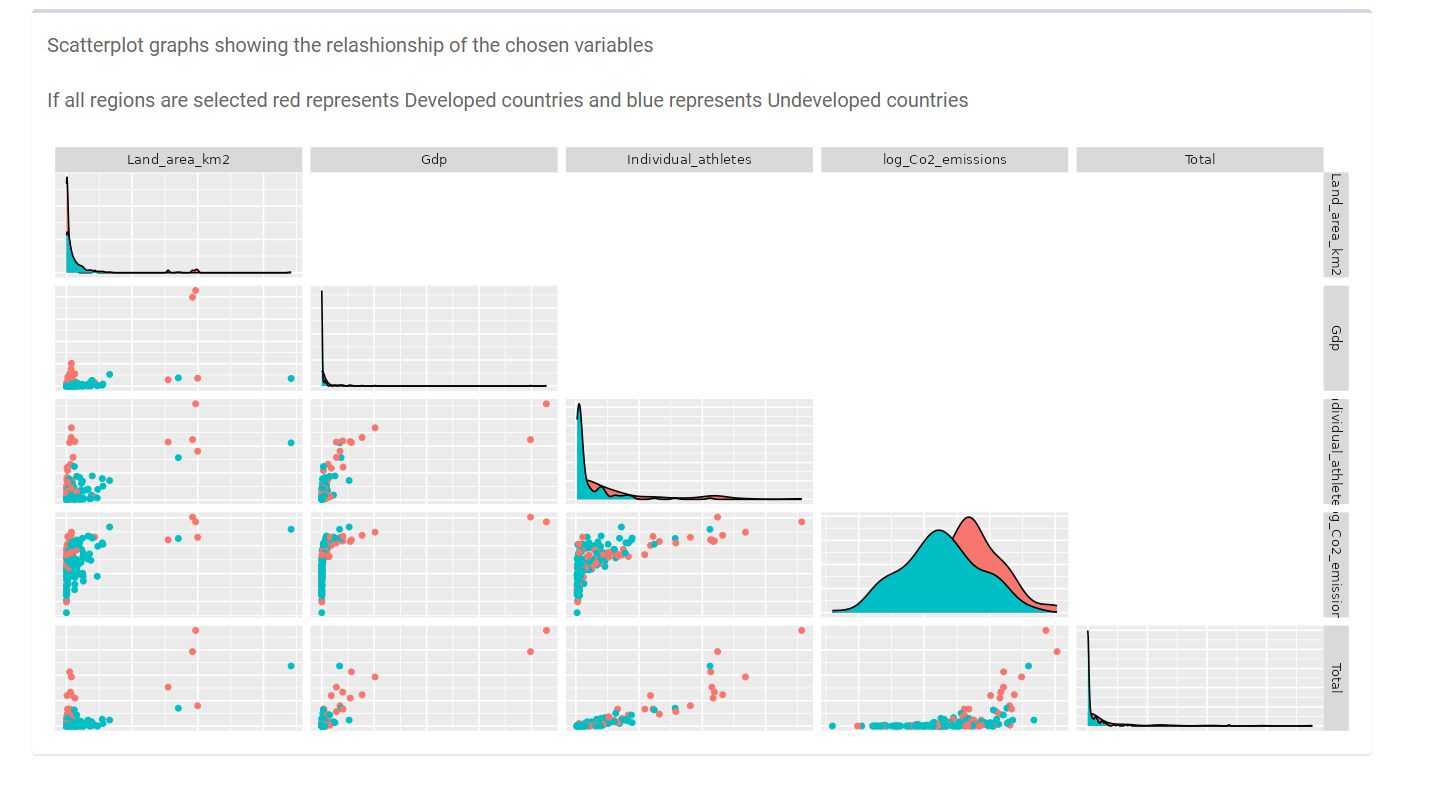
Assumptions:
- Multicollinearity
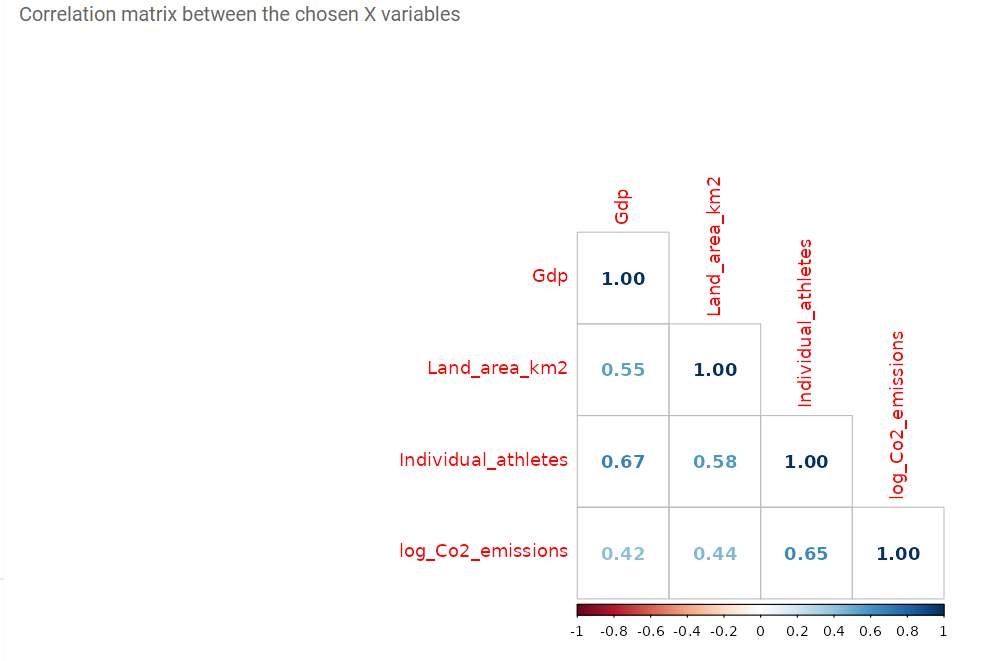
The independent variables are not highly correlated between each other, showing the lack of multicollinearity
II . Constant Variance, Independent error and Normality
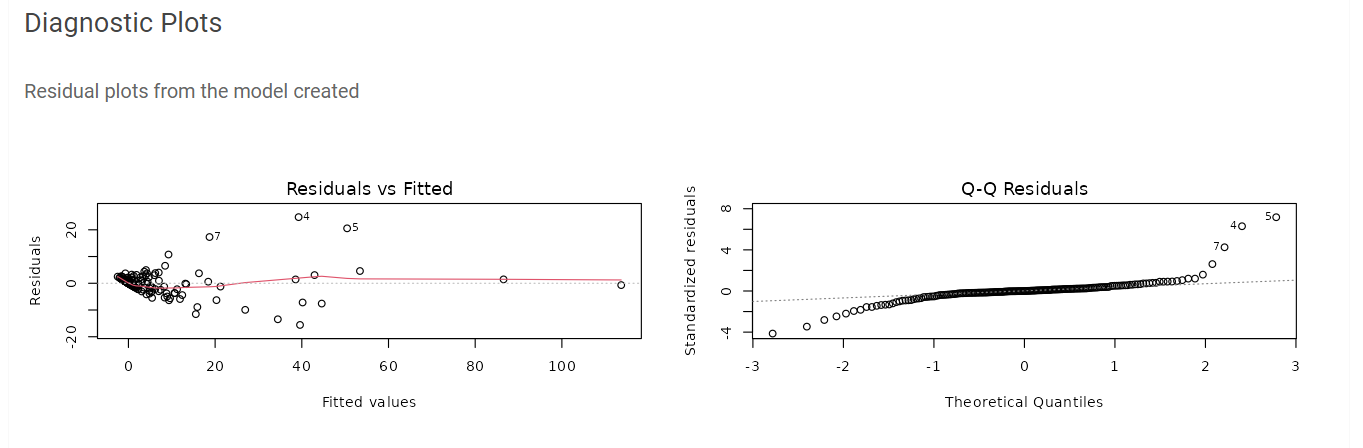
In the Residuals vs Fitted graph the errors appear to have a constant variance (red line is straight at zero in the Y axis) and look independent.
In the Q-Q Residuals graph we can see that the error follow a normal distribution
Model interpretation
The equation shown below has the total number of medals won in all countries as the dependent variable, but if the dependent variable were another of the possible available selections, the result would be quite similar.
Best Model:
Green color was used for increases and red for decreases.
Total = 3.3663 + 0.8814 * Land_area_km2 + 0.000002 * Gdp + 0.1733 * Individual_athletes - 0.6002 * log_Co2_emissions
Interpretation:
92.27% of the variability of the total number of medals won by all countries in the 2020 summer olympics is explained by the 4 variables listed bellow:
- Land_area_km2: For each million square-kilometer increase in land area, there is an average increase of 0.8814 medals won, keeping everything else constant
- Gdp: For every dollar increase in the Gdp, there is an average increase of 0.000002 medals won, keeping everything else constant
- Individual_athletes: With every additional athlete participating in the games for an individual sport there is an increase of 0.1733 medals won, keeping everything else constant
- log_Co2_emissions: For an 1% increase in carbon dioxide emissions in tons, there is an average decrease of 0.6002 medals won, keeping everything else constant
However, if the same model were used only for underdeveloped countries, it would not satisfy the assumptions of multiple linear regression, though it would work for developed countries.For underdeveloped countries, a model with only the number of individual athletes already yields an R² of approximately 70%.
Real X Estimate
The table below showcases the model's accuracy, indicating that it successfully predicted the number of medals obtained for certain countries like the United States and China. However, it did not perform as well for countries such as Russia and Great Britain. Notably, the model also demonstrated proficiency in predicting medal counts for countries that did not win any medals.

Future work
For future work I would like to analyze other Summer Olympics games to determine if the same model is applicable. Also, examine the most recent Winter Olympic games to assess how well the model works in that context.