Predicting Automation from Job Descriptions
Contributed by Tomas Kolasa. He took the course in the NYC Data Science Academy 12 week full time Data Science Bootcamp program taking place between January 11th to April 1st, 2016. This post is based on his capstone project (due on the 12th week of the program).
For this project, I applied Frey and Osborne's probabilities of occupation computerization to scraped job description data. Using natural language processing (NLP) and semi-supervised learning, I created a basic model that predicts a job's automatability based on its text description. This model can take in any new job description and return its corresponding probability of automation.
Automation is no new concept. Whether the automation of hand knitters from the invention of the stocking frame knitting machine in the 16th century or the obsolescence of guilds from the development of new technology, there was always a threat that a worker might lose her livelihood. However, with recent exponential advances in computational power and robotics, the economy faces never before seen threats to employment, including for highly cognitive tasks.
Background Source Paper
In 2013, Carl Benedikt Frey and Michael A. Osborne of Oxford published The Future of Employment: How Susceptible are Jobs to Computerisation?. They studied 702 occupations listed by the US Department of Labor and examined each for nine factors determined by the Occupational Information Network (O*NET) database.
Using this database, labor non-susceptible to automation can be represented by the following:
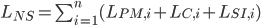
Where 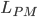 is labor entailing perception and manipulation,
is labor entailing perception and manipulation, 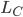 is labor entailing creative intelligence, and
is labor entailing creative intelligence, and 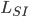 is labor entailing social intelligence. Each of these factors subdivides in the following table from the paper:
is labor entailing social intelligence. Each of these factors subdivides in the following table from the paper:

The team of machine learning researchers next asked, “Can the tasks of this job be sufficiently specified, conditional on the availability of big data, to be performed by state of the art computer-controlled equipment.” Using O*NET data on each occupation, they subjectively labeled 70 occupations where a label of 1 corresponds to fully automatable occupations and 0 corresponds to a non-automatable occupation. This probability denotes how easy or difficult it is to automate an occupation, not whether macroeconomic forces and policy decisions will actually lead to a specific occupation's automation.
After labeling these 70 occupations, the authors used a Gaussian Process Classifier to estimate the probability of automation for the remaining occupations.
For each of the nine O*NET variables, the authors plotted each occupation's variable score with the estimated probability of automation. As the following scatter plots show, there is a lower probability of computerization for occupations with higher scores for assisting/caring for others, persuasion, negotiation, social perceptiveness, artistry, and originality. The opposite is true for the perception and manipulation variables of manual dexterity, finger dexterity, and cramped work space.

Scraping Job Descriptions
For each of the 702 occupations, I searched a popular public job listing site. Since many of the Department of Labor occupations use old terminology, I manually checked the results of each search to monitor quality. To distinguish between similar jobs that may come up in results for differing occupations (such as for dentist vs. dental assistant), I set more detailed search criteria such as job title when possible. Even though this process consumed many hours of time, it was necessary to ensure authentic and actionable results.
Of the original occupations, 569 had search results. As shown in the histogram below, most of those occupations had a very high or low probability of computerization.

Although some occupations have many results, I limited the number of descriptions to 1,000 per occupation. I thus had a stratified sample of at most the first 1,000 descriptions per occupation, making a total of 260,000 job descriptions.
Natural Language Processing
To analyze the text, I used the Natural Language Toolkit (NLTK) to remove stop words, tokenize, and stem the text corpus's vocabulary.
To compare the different occupations, I calculated the tf-idf (term frequency–inverse document frequency) of the job descriptions. This metric determines the importance of a word to a document in a collection of documents. To use the scikit-learn's implementation of tf-idf in Python, the corpus size was still too large. To speed up the process, I only calculated it for the first 100 job descriptions for each occupation.
Semi-Supervised Learning
Before modeling, I still had to simplify the problem further. Instead of classifying a job description as belonging to one of the 569 labeled occupations, I first broke down the occupations into clusters based on the tf-idf vectors for each occupation.
Looking at hierarchical clustering of the occupations using the Ward's method, the dendrogram does not exhibit lopsidedness. This is evidence that clustering the occupations is a valid method. Similar occupations exhibit subjective similarities between them, unofficially corroborating agglomerative clustering
Click the dendrogram below to expand in a new tab

Performing k-means clustering over many values of k, there is not a number of clusters that cleanly groups the data, as shown in the following scree plot of the within-cluster sum of squared errors.

Nevertheless, the more important measure for modeling prediction is the probability of automation of the occupations within each cluster. For a cluster to to benefit automation prediction, the occupations within it should all have similar probabilities of automation. If so, I can safely assign a new job description to that cluster and simply give the average automation probability of that cluster.
Looking at many different values of k, I measured each cluster's standard deviation of automation probability. I then took the weighted average of all the clusters to give more weight for clusters with more occupations in them than others. In the graph below, the standard deviation decreases as the number of clusters increases.

I first examined a k of 10 because that number of clusters or greater covers the most significant drop of within-cluster standard deviations. The clustering results are summarized in the following table:
| Cluster | Key Words | Sample Predicted Occupations | Automation Probability |
Stand. Dev. |
| 0 | sale, marketing, clients, design, retail | Fashion Designers, Real Estate Brokers, Theatrical and Performance, Marketing Managers, Insurance Sales Agents, Telemarketers | 0.26 | 0.30 |
| 1 | machines, tools, machines, manufacturing, materials | Machinists, Rolling Machine Setters, Coremaking, Underground Mining, Tool & Die Makers, Sawing Machine Setters/Operators, Computer-Controlled Machine Tool Operators | 0.73 | 0.17 |
| 2 | student, volunteer, classroom, volunteer, provided | Teachers, Teacher Assistants, Sociologists, Librarians, Coaches and Scouts, Referees | 0.28 | 0.33 |
| 3 | assemble, manufacturing, metal, tools, fabrication | Metal/Plastic Engine/Machine Assemblers, Electromechanical Equipment Assemblers, Furnace/Kiln/Oven/Drier Operators/Tenders, Welding/Soldering/Brazing Machine Setters | 0.69 | 0.30 |
| 4 | guests, clean, food | Baggage Porters and Bellhops, Gaming Managers, Cooks, Massage Therapists, Hotel Desk Clerks | 0.13 | 0.22 |
| 5 | safety, driver, clean, materials, vehicle | Locomotive Engineers, Flight Attendants, Embalmers, Truck Drivers, Refuse and Recyclable Material Collectors, Log Graders and Scalers, Janitors and Cleaners | 0.70 | 0.25 |
| 6 | engineers, projects, design, data, technical | Mechanical Drafters, Petroleum Engineers, Environmental Engineers, Economists, Geoscientists, Logisticians, Nuclear Engineers, Civil Engineering Technicians, Actuaries | 0.84 | 0.22 |
| 7 | care, medical, health, treatments, physician | Physical Therapists, Orthodontists, Social Workers, Pharmacy Aides, Physicists, Dental Laboratory Technicians, Psychologists, Physicians and Surgeons | 0.31 | 0.36 |
| 8 | office, accounting, process, documents, clients | Judges, Judicial Law Clerks, Tax Examiners and Collectors, Claims Adjusters/Examiners/Investigators, Probation Officers and Correctional Treatment Specialists | 0.53 | 0.39 |
| 9 | repair, maintenance, installation, electrical, technician | Plant and System Operators, Environmental Science and Protection Technicians, Plumbers/Pipefitters/Steamfitters, Boilermakers, Bus and Truck Mechanics | 0.83 | 0.17 |
Although some clusters, especially clusters 4 and 9, do a good job of grouping occupations with similar probabilities of automation, others make some mistakes. For example, there is a 0.99 probability that employers can automate telemarketers when the clustering groups telemarketers into cluster 0 with a 0.26 probability of computerization.
This is partially due to the nature of clustering along probabilities between 0 to 1. For clusters with average probabilities near 0 or 1, the observations of a cluster have a smaller variance of automation probabilities because a single occupation's probability cannot be less than 0 or greater than 1. This relationship is shown in the following graphs for 10, 20, and 50 clusters. This means clusters with very low or very high probability of automation have more exact predictions.



Fitting a Model and Making Predictions
To fit job descriptions, I used a Naïve Bayes Classifier. Since the main assumption of Naïve Bayes is independence of features, the model assumes the occurrence of any two words is independent and that the location of a word is independent of its occurrence in the document. The model classifies a job in a cluster and I assign that cluster's probability of automation to that job.
To run the model on a new job description, I first must calculate its tf-idf vector. I then use my classification model to find the most appropriate cluster for the new job description. I then take that cluster's probability of automation and return it as the predicted probability of automation of the new job description. I made it into the final function below:
def job_automation_predictor(description):
features_test = tfidf_vectorizer.transform([description])
cluster = clf.predict(features_test.toarray())[0]
print ('Cluster', cluster)
print ('Probability of automation:', groupedc10.mean()[cluster])
print ('Automation standard deviation:', groupedc10.std()[cluster])
print ('Key words:',key_words['Cluster ' + str(cluster)])
For example, the following new job description of a Facility Maintenance Technician has its corresponding function output below:
Commercial and residential property management company is currently looking for mid level facility maintenance technicians. Candidates will be responsible for: Keeping grounds clean. Basic janitorial duties. Keeping exterior area’s trimmed and mowed. Hanging seasonal decorations and lighting. Operating forklifts. Basic HVAC experience required. Desired Skills and Experience Must have a valid drivers license. Pre-employment drug screen and background check required.
Cluster 9 Probability of automation: 0.826296296296 Automation standard deviation: 0.171808321193 Key words:repair, maintenance, installation, electrical, technician
While the model gives a logical classification for this job, others descriptions do not always fare so well. There is still plenty of room for improving the model, especially by tuning the tf-idf parameters. Running the models with more data will be more time-consuming, but will hopefully gather more accurate insights for prediction. After tuning the model in the coming weeks, I plan to build a web application where a user can input any job description to better understand its risk of automation.
Although I would like to conclude on an optimistic note about how artificial intelligence will greatly improve overall economic productivity, that would not do justice to the millions of citizens who will face threats to their livelihoods unless governments work to greatly overhaul labor education and training.