Muse: a Better Music Recommendation Application
App: (LINK SOON) Github: Github
Preface
The average American spends 4 hours a day listening to music (SPIN) and 93% of Americans listen to music daily in some capacity (EDISON). Almost half of that listening is via AM/FM radio, but music streaming services are gaining a greater and greater market share and have even turned around the declining revenues of the music industry.


This success breeds competition among streaming providers to increase customer acquisition and retention by creating music recommendation algorithms that have just the right ingredients to serve up the tunes their customers crave.
Current Market
Let’s first take a look at one of the pioneers in the music streaming service world: Pandora. Pandora was established in 2001 and has had a decreasing market share among newer streaming competitors.

Why is this? I personally believe it is because of the nature of the recommendations on Pandora. Pandora only allows users to create playlists based on one artist or song, which often doesn’t encapsulate the original mood the listener was looking for and yields poor suggestions that often are repeated after as little as 10 songs later. On the other end of the streaming service spectrum are platforms like 8 tracks, which do suggest playlists that a user may be interested in listening, but all of these playlists have to be manually created by users. Services like 8 tracks have more dynamic playlists than Pandora, but again these services rely on users to actively create playlists and then suggesting the correct playlists to users. Somewhere in the middle of the human editorial and algorithmically generated playlist spectrum of music streaming services is Spotify. This compromise is one of the main reasons Spotify has the largest market share as of March 2016.
Spotify uses a combination of collaborative filtering and other playlist statistics to suggest very poignant songs to users that feel like that music guru friend you trust is making the suggestion. Spotify's collaborative filtering works by analyzing a users' playlist and finding other users' playlists that have the same songs, but maybe a a few more, and then will suggest those additional songs to the original user. Spotify not only uses this method for song suggestion, but also weights songs based on whether a user favorited it and listened to it many times following the initial like or even when a user is suggested a song and skips it within the first minute. Because of this combination of collaborative filtering and certain statistics tracking, Spotify can suggest extremely accurate song recommendations that feel eerily familiar. As great as Spotify's recommendation engine is, what if there was way to build upon its already impressive algorithm and to suggest songs that are even more playlist specific.
Enter Muse
The general concept behind Muse is simple. Where Pandora suggests songs based on a single seed artist or song, Muse takes into account an entire playlist, the attributes of each song within a playlist, and the play counts of each song to form a better query on the new Spotify API endpoint for recommendations.
In early 2014, Spotify acquired EchoNest; the industry’s leading music intelligence company, providing developers with the deepest understanding of music content and music fans. Through the use of Spotify's API, which now allows access to these EchoNest services, developers can provide seed information and target attributes in a query and the API will send back recommended songs in its response. This EchoNest API endpoint is the backbone of many suggestive services like Shazam, Pandora etc.., As you can probably imagine, choosing the best query parameters is thus very important and indeed this is what determines the accuracy and relevance os the recommendations the API responds with. As stated previously, Muse optimizes these query parameters to be as representative of an entire playlist as possible and therefore bring back recommendations that are more relevant. So how does Muse do it?
The Muse Algorithm

Upon login via Spotify oAuth, users automatically see their local iTunes playlists and Spotify playlists on the left-hand column. If for some reason, their iTunes Library XML file is not at a standard location on their computer, users can specify the correct path for Muse to look for the file.

From here, a user can click on a playlist, which is where the magic of Muse takes place through the following algorithmic process which I have appended a diagram below followed by bullet points to explain each step in greater detail:

- Upon choosing a playlist, Muse will send each song within the playlist to Spotify's API to get back the attributes of the song including tempo, danceability, energy etc..
- Muse will then multiply the song attribute object by the play count for that song. For instance, if song A has a play count of 30 and song B a play count of 10, there will be 29 duplicates of the attribute object for song A and 9 duplicates of the attribute object for song B going into step 3.
- Muse then finds the weighted average of these songs to create the Phantom Average Track, which is an attribute object that best represents the composition or mood of the entire playlist.
- Muse then uses the artists of the five songs with the shortest Euclidian distances to the Phantom Average Track as seed artists as well the Phantom Average Tracks's attributes as target attributes to send to Spotify''s API to find recommended songs.
- The recommended songs sent back from Spotify are filtered to remove any duplicates with the original playlist and then sorted by relevance as defined by the Euclidean distance of the song's attributes from the original playlist's Phantom Average Track's attributes
Once the Muse algorithm has completed, users can then click on any recommended song. The chosen song's title and artist name will then be used to query YouTube's API and return and then play the top related video. Users can also click the play button which will play both playlist tracks and recommendations in order by relevance score.

Users can then drag recommendations they like into their playlist, which changes the composition of their playlist thus triggering the Muse algorithm to rerun and get new relevance scores and recommendations based on the playlist with the newly added song.

Automatic Playlist Generation
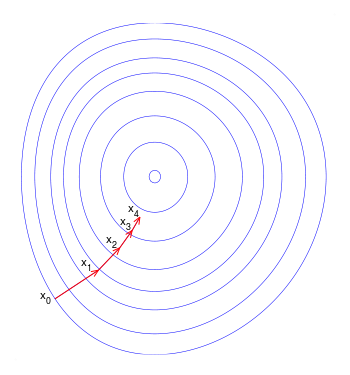
Although this feature is not entirely implemented yet, it is easy to imagine that a form could be put in place that would prompt a user to select a playlist, how many new songs or how many additional minutes of music they are looking for as well as how much variability in the new recommendations they would like and Muse could automatically add the number of recommendations needed to meet the expanded playlist criteria. For example, if the user wanted to add 5 new songs to the playlist that were most similar to the original playlist (by specifying low variability) then with each added recommendation sorted by relevance, the variance of the playlists' attributes would tighten as illustrated below. On the other hand, if a user wanted to add 5 new songs that were similar but not too similar, Muse would add recommendations with lower relevance to the original playlist, which would still approach a low variance minimum for playlist attributes as illustrated below again, but at a slower rate, which in turn would expand the variability of the new playlist's songs.

{kind=link}
Recursive Playlist Generation
However, a more interesting algorithm than this would be to let Muse run as it is described in the previous flow chart where with the addition of each recommendation, Muse would recompile the playlist's phantom average track based on the playlist that now contains an additional song and add a then fetch potentially completely different recommendations. This process would then continue recursively until an entire playlist with new recommendation was reached with specified duration or threshold level. This can be best visualized using a similar workflow as the one described previously, but with the addition of a final recursive step.

The application of this recursive playlist generation is very interesting for its potential to create varied suggestions through a unique decision path. For example, if the user wanted to to expand a current playlist by 10 songs that were as similar to the original playlist as possible by specifying a low recommendation relevance, then Muse would add the top recommendation with each recursive iteration and approach a playlist attribute variance minimum as fast as possible until the playlist duration or number of intended songs was achieved.

Yet, if a low enough recommendation relevance was set by the user (say 70%), then with each recursive iteration, Muse would add the recommendation with a relevance score closest to 70% which would mean that playlist generation may take a slower, more circuitous route towards the playlist attribute variance minimum.

The best way to visualize this process is to imagine falling down a whirlpool. The initial width of whirlpool may be wide, similar to a playlist you may have containing songs with varying attributes, but as you fall further into the whirlpool, its width tightens and the playlist's variance of song attributes approaches a minimum. It is important to note though, that like how a whirlpool twists and turns away from the center as it approaches its minimum, so too does the variability of recommended songs with each recursive step meaning that each added recommendation brings you closer to the bottom of the whirlpool, but may pull you in different directions throughout its descent depending on the variability of the recommendations. Finally, the pace at which you are pulled down the whirlpool creating a tighter playlist variance is defined by the recommendation relevance level initially set in the playlist generation form.
Billboard Playlisting
One final unique feature of Muse is that it allows users to create a playlist based of the Billboard Top 100 for any days since Billboard's inception. A user can click on the top bottom left of the screen to change the date and Muse will use Selenium to inject the specified date into this site and then web-scrape the top 100 results to create a new playlist. Muse will then weight these songs by the number of weeks the spent on the charts and find recommended songs that sound like the top hits from that day, but could be from any era.

Further Work
- Set up unique user accounts using Firebase so as to only require initial playlist seeding by Spotify and iTunes once and to store additional metrics to improve the algorithm including skipping of songs and colloborative filtering
- Create the form mentioned previously to recursively generate entire playlists given user specifications
- Deploy as Beta application
- Compared recommendation success to other streaming services
Specifications
View full project on Github
Muse was created using:
- Python Flask backend
- Spotify API for music attirbutes and recommendations
- YouTube API for video suggestions
- Material-UI and Jquery UI for front-end design
- Selenium for web scraping