Utilizing Data to Predict and Characterize Healthcare Fraud
The skills I demoed here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.
GitHub
Introduction
The National Health Care Anti-Fraud Association data estimates conservatively that healthcare fraud costs the nation about $68 billion every year. Often it comes from clinics and hospitals overcharging insurance companies by submitting fraudulent claims. There is a 30-day investigation limit for claims that are potentially fraudulent. This time constraint makes it difficult to do an adequate investigation before the insurance company has to pay, which means these frauds often remain undetected. When insurance companies suffer losses, it makes it up by raising premiums. That means that we all, as patients and consumers, end up paying for fraud.
Objectives
- Build a predictive model to help insurance companies detect potential fraudulent providers in order to reduce financial losses.
- Identify the characteristics and behavior of potential fraudulent providers to inform and advise insurance companies for potential notification and alert systems.
Data description
The data for this project was retrieved from: https://www.kaggle.com/rohitrox/healthcare-provider-fraud-detection-analysis
The data is comprised of four datasets below:
- Inpatient records: over 40k records, including doctor IDs, provider IDs (clinic/hospital IDs), patient IDs, diagnosis codes, operation code, reimbursement information, etc.
- Outpatient records: over 500k records with similar features to inpatient records.
- Beneficiary records: over 130k patients with their pre-existing chronic conditions.
- Fraudulent flags at the Provider level: about 9% of all providers were flagged with possible fraud.
Challenge of the dataset
- Imbalanced dataset: The potentially-fraudulent providers make up only 9% of the total dataset.
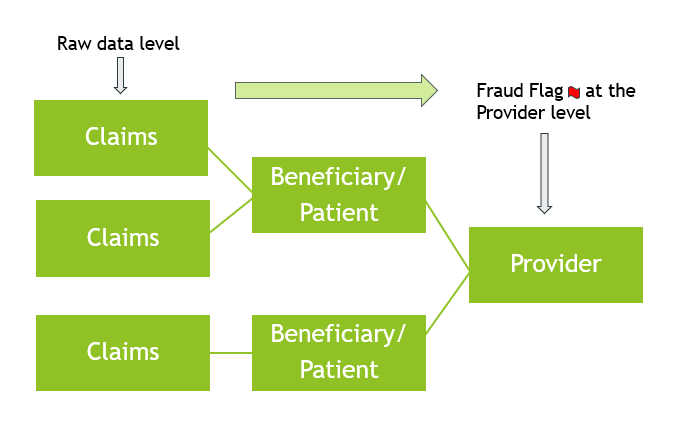
- Different levels of data: We had to bring the raw data from the Claims level to the Provider level first by aggregating and feature engineering(discussed later) before we could do any modeling because that is where the response variable was. The 3 different levels were:
- Claims level: Our dataset started at the claims level with outpatient and inpatient records.
- Beneficiary level: Beneficiaries or patients can have one or more claims, depending on the diagnosis and the treatment they receive.
- Provider level: Providers are practices and hospitals that provide medical services. Each provider can have multiple patients/beneficiaries. We can think of providers being at the highest level, which is where they are flagged as potentially fraudulent or non-fraudulent.
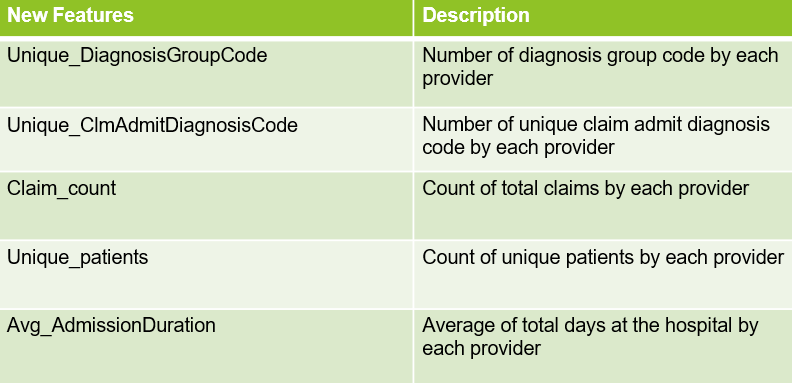
Data on Feature Engineering
In the process of bringing the data from the claims level to the provider level, we merged all the datasets - inpatient, outpatient, and beneficiary - into one main dataset. Then we aggregated and transformed the data to the provider level so we could add the potential fraudulent flags. As a result, we engineered 35 new features. Below is a list of some of the engineered features that were also found to be important in predicting potential fraudulent providers during modeling.
Exploratory Data Analysis (EDA)
Once we had all the features at the provider level, we were ready to do Exploratory Data Analysis. Below are some of the insights we found from our analysis.
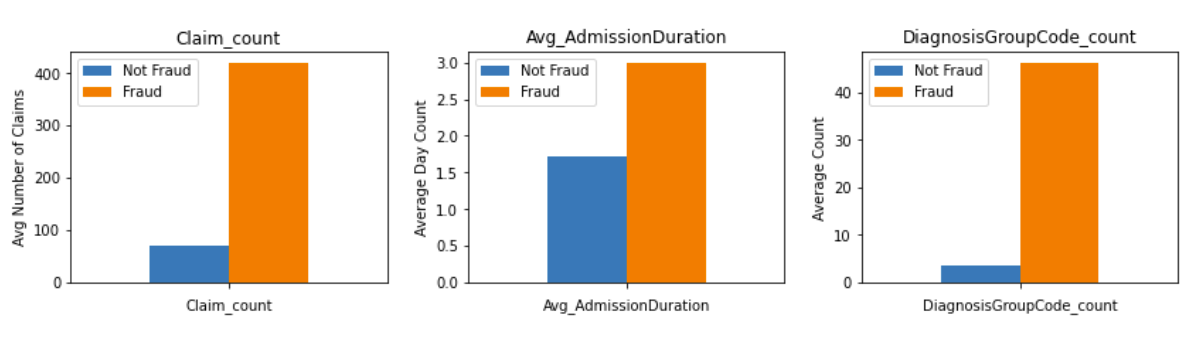
According to the bar plots above, we found that
- Potential fraudulent providers on an average had more claim counts than non-fraudulent providers.
- Potential fraudulent providers have a much higher average number of diagnosis group codes than non fraudulent providers.
- The patients under potential fraudulent providers have longer hospital stays than non fraudulent providers.

The scatterplot above shows the relationship between the number of unique counties and claim count. We found that with an increase in the number of unique counties, the probability of the provider being potentially fraudulent increased.
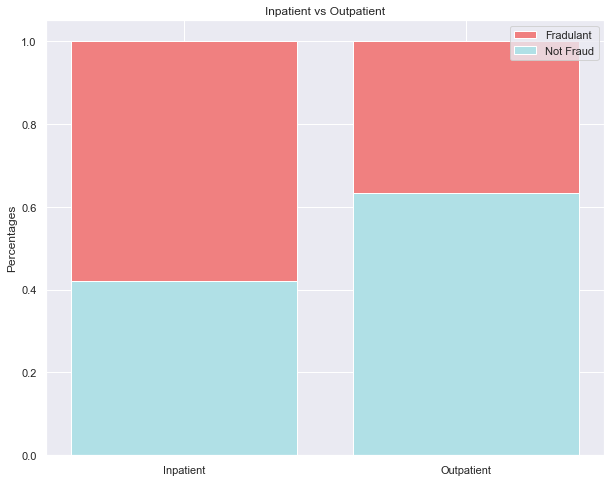
Inpatients are patients who stay overnight or longer at the hospital; outpatients are people who visit the hospital for their particular cause and leave within the same day. The stacked bar chart above shows that potentially fraudulent providers service more inpatients than outpatients.
Modeling
Due to the imbalance of the fraudulent/non-fraudulent providers, we decided to upsample the observations with fraudulent providers, as they were the minority class. Using SMOTE, we upsampled our observations with fraudulent providers from 9% to 30%. SMOTE creates new observations of the minority class by creating convex combinations of neighboring observations, as opposed to duplicating the existing minority class observations. Afterwards, we had to normalize the data using StandardScalar. Then, we were ready to model.
First, we started with Logistic Regression using gridsearch as a baseline for model comparison. Our Logistic Regression chose an l1(Lasso) penalty from its best parameters, so we decided to use Lasso to look at what features were kept. Next, Lasso kept 17 features to be important in identifying potentially fraudulent providers. Afterwards, we trained non-linear models, such as Random Forest, Support Vector Classifier (SVC), and Gradient Boosting Classifier, with the original 35 features to see if they would choose any different features than what Lasso kept due to non-linear relationships.
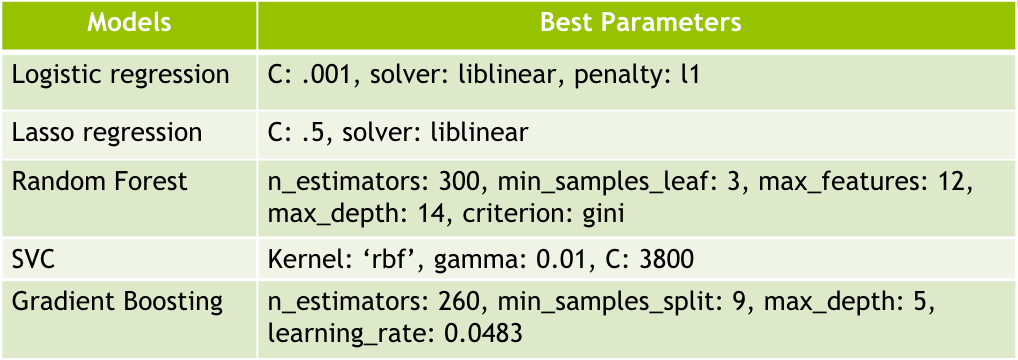
Below are the best parameters that each model came up with through gridsearch:
Also, we saw that there were common features that were found most significant among all the models. They are marked on the following graphs in blue boxes.
Lasso Features:

Random Forest - Top Features:

Gradient Boosting Classifier - Top Features:

From these models, we gathered our best AUC_ROC and recall scores to determine our best model to identify potentially fraudulent providers.
Model Selection:
From the five different models we trained, Support Vector Classifier had the best overall score as well as the recall score as seen from the figures below. We prioritized the Recall score because we wanted to ensure each potentially fraudulent provider getting detected as fraudulent over non-fraudulent providers getting mis-flagged as fraudulent.
Recall Definition in our case is:

With this in mind, we took the overall score into account by averaging both the AUC_ROC accuracy score and the recall score. The following figure shows the scores obtained by all the models in comparison to each other.

We chose the Support Vector Classifier (SVC) as our best model since it had the best overall score of 0.783, taking into account both the recall score (0.677) as well as the AUC_ROC Accuracy score (0.888):

Using the confusion matrix, our best model SVC had identified 103 potentially fraudulent providers correctly, and we will be using this result in our business case:

Business Case & Recommendations:
Keeping in mind the risk of lawsuit and litigation due to mis-classifying non-fraudulent providers as potentially fraudulent, we recommend insurance companies use our best model, SVC, as a guide to shortlist their providers. These providers can then be screened through a more rigorous review based on the following characteristics we found common among potentially fraudulent providers:
- They use 43 more Diagnosis Group Codes on average than non-fraudulent providers.
- On average they process 350 more claims than non-fraudulent providers.
- They provide coverage in 14 more unique counties than non-fraudulent providers.
- Their patients have 1.3 more days of hospital stay on average than those of non-fraudulent providers.
For the potentially fraudulent providers that are filtered through the characteristics and found guilty upon the insurance companies’ rigorous screening, the potential cost savings from utilizing our best model could amount to $70,746,183.40 based on taking the product of the following values computed from our dataset:
155 (median claims per provider) x $4431.33 (average claim cost per provider) x 103 (providers identified as fraudulent) = $70,746,183.40 (savings per year)
Conclusion:
Finally, we have seen how complex and hard-to-track healthcare fraud is from our analysis as it is a crime that can hide itself in a variety of ways and involve multiple parties. With that said, we have found the top important features contributing to the likelihood of potential fraudulent providers to be:
- Unique Diagnosis Group Code
- Unique Claim Admit Diagnosis Code
- Claim count
- Admission Duration
- Unique patients
Red flags include proxying for characteristics, such as providers using more unique diagnosis group codes as well as admittance diagnosis codes, perhaps for misrepresenting the nature of the actual service to make it more expensive or to fabricate claims out of thin air. It can be seen from the data that not only is the hospital stay longer on average with potential fraudulent providers, but also the number of claims is higher. This means that the business volume is greater, suggesting larger hospitals and clinics. Furthermore, the number of unique patients was an important feature for all of our models (negative for lasso) suggesting that potential fraudulent providers had more repeat patients.
Lastly, for further analysis, we would like to get more clearly labeled data that is representative of certain regions within the U.S, as we were not able to make further conclusions without making major assumptions. Using this type of representative data, we would like to build a potential fraudulent provider notification and tracking system that filters providers based on certain characteristic thresholds. Doing so and utilizing our best model will not only save the insurance companies from financial loss, but also will save patients from paying higher health insurance premiums while stopping bad apples from thriving on this white-collar crime.